Group Cursor in esProc
Published on 29 August 14
 Raqsoft
Raqsoft0
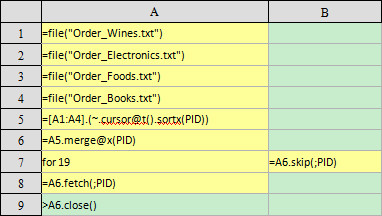
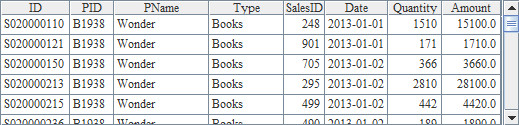
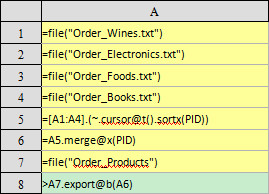
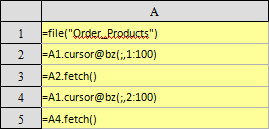
This blog is listed under
Data & Information Management
Community
Related Posts:
Post a Comment








