Simplifies SQL-style Computations - In-group Computation
Published on 06 November 14
 Machine
Machine0
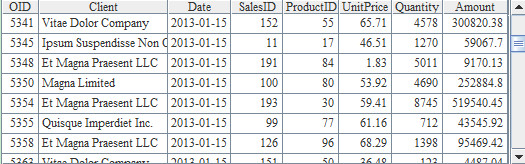
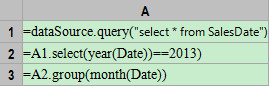
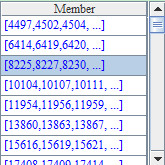
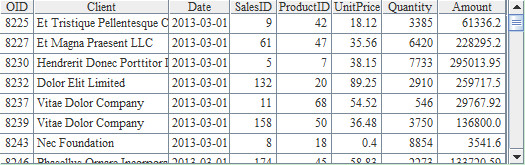
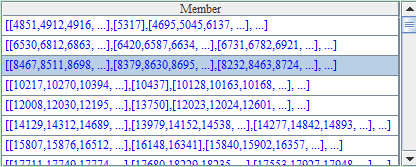
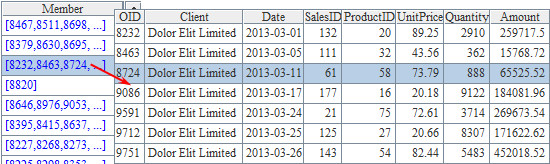
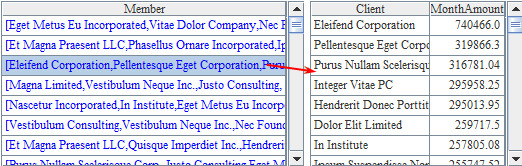

This blog is listed under
Development & Implementations
and Data & Information Management
Community
Related Posts:
Post a Comment








