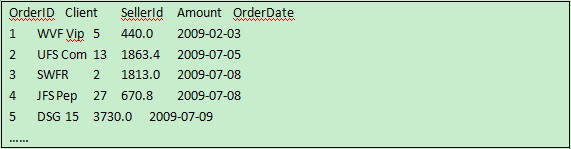
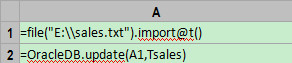
In the above script, import function is used to import the text file. tab is the column separator by default and the option @t means the first row is set as the column name. update function is used to import the data in A1 into the database in batches. OracleDB is the name of data source. Tsales is the table name.
With the script, all data has been imported into the database. Then we just need to call the script in Java code.
// create a connection using esProc jdbc
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
// call the esProc script, whose name is test.
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call test(?)");
// execute the esProc script in a similar way as executing the stored procedure
st.execute();
After the above Java code is executed, sales.txt is imported by the esProc engine into table Tsales.
This script written in esProc is simple, so it can be embedded directly in Java code without creating a script file. The code is written as follows:
st.executeQuery("=OracleDB.update(file("E:\\sales.txt").import@t(),Tsales)");
Sometimes the table in the database may not be empty. In this case, we shouldn’t import all data into it. We should first compare the data in the file with that in the table according to the primary keys instead. update statements will be generated if the data shares the same primary key and insert statements will be generated if the primary keys in the text file cannot be found in the table. There are several situations:
If the table in the database already has primary keys (it is OrderID in this example), the code remains the same as that in the above. In other words, the esProc engine can automatically compare the primary keys (including composite primary keys) of the database with the fields of the text file and generate corresponding update statements or insert statements.
But if there are no primary keys in the table, we just need to set them manually in the update function, that is, change the script in cell A2 into =OracleDB.update(A1,Tsales;OrderID).
If we don’t want to change the original data in the table, we need to add a function option @i to the script to make esProc generate the insert statements only, like =OracleDB.update@i(A1,Tsales). Similarly, option @u means generating update statements only.
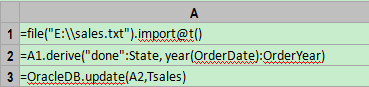
In the example above, we assumed that the table in the database and the text file are of the same structure. But, in reality, they may not have the same structure. For example, the table has three more fields than the text file: State, OrderYear and Memo. It is required to fill a default value done in the field State of the table, compute the years of OrderYear according to the data of OrderDate, and make Memo remains empty. To solve this problem, we just need to write script as follows:  Machine
Machine