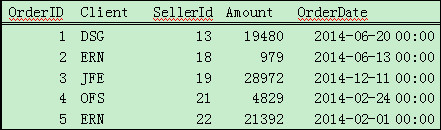
derive function is used to add new columns to an existing table sequence so as to form a new one. For example, derive(1) means adding one column, where 1 is the field name and the field value is the same as the column name. derive(0:field1, null:field2) means adding two columns, where, respectively, field names are field1 and field2 and field values are 0 and null.
According to the requirement of transposition, twelve columns should be added here, for which the code should be derive(1,2,3,4,5,6,7,8,9,10,11,12). A macro, that is ${}, whose role is to convert a string into an expression, is used here in order to generate the code dynamically. to(A1.len()) in the macro is a sequence, whose value is [1,2,3,4,5,6,7,8,9,10,11,12]. The function string() is used to convert the sequence into the string “1,2,3,4,5,6,7,8,9,10,11,12â€.
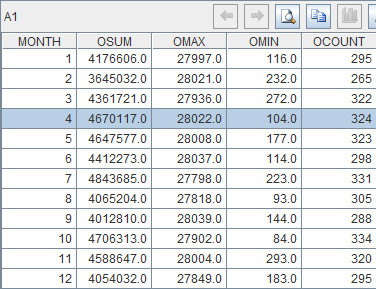
A3-A5:Perform loop on A1, accessing one record each time, rearranging it vertically and, at the same time, modifying the corresponding column in the table sequence in B2. Please note the working range of the loop statement can be represented by the indentation, with no need of using braces ({}), or begin/end. So both B4 and B5 are in the working range and neither A4 nor A5 is in it.
Note: In esProc’s loop body, the loop variable is the cell where for statement is entered. In other word, A3 can be used to reference the current record and A3.MONTH can be used to reference the MONTH field of the current record.
B4=A3.OSum | A3.OMAX | A3.OMIN | A3.OCount
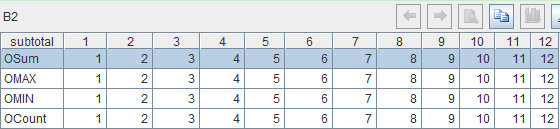
This line of code concatenates the summarized fields of the current record in columns. The operator “|†represents concatenation. For example, the records of December in A1 should be like this after being concatenated:  Machine
Machine