Bad Practices in Database Design: Are You Making These Mistakes?
Published on 25 October 17
 Michelle
Michelle0
0
Whenever you, as a developer, are given a task based on existing code, you have to face many challenges. One such challenge—more often than not the most demanding one—involves understanding the data model of an application.
You are faced normally with confusing tables, views, columns, values, stored procedures, functions, constraints, and triggers that take a long time to make sense to you. And, once they do, you start noticing many ways to improve and take advantage of the stored information.
If you are an experienced developer, chances are you will also notice things that could have been done better in the beginning, i.e., design flaws.

In this article, you will learn about some of the common database design bad practices, why they are bad, and how you can avoid them.
Bad Practice No. 1: Ignoring the Purpose of the Data
Data is stored to be consumed later, and the goal is always to store it and retrieve it in the most efficient manner. To achieve this, the database designer must know in advance what the data is going to represent, how is it going to be acquired and at what rate, what its operational volume will be (i.e., how much data is expected), and, finally, how it is going to be used.
For example, an industrial information system where data is gathered manually every day will not have the same data model as an industrial system where information is generated in real time. Why? Because it is very different handling a few hundreds or thousands of records per month compared with managing millions of them in the same period. Special considerations must be made by the designers in order to keep the efficiency and usability of the
But, of course, data volume is not the only aspect to consider, since the purpose of the data also affects the level of normalization, the data structure, the record size, and the general implementation of the whole system.
Therefore, thoroughly knowing the purpose of the data system you will create leads to considerations in the choice of the database engine, the entities to design, the record size and format, and the database engine management policies.
Ignoring these goals will lead to designs that are flawed in their basics, although structurally and mathematically correct.
Bad Practice No. 2: Poor Normalization
Designing a database is not a deterministic task; two database designers may follow all the rules and normalization principles for a given problem, and in most
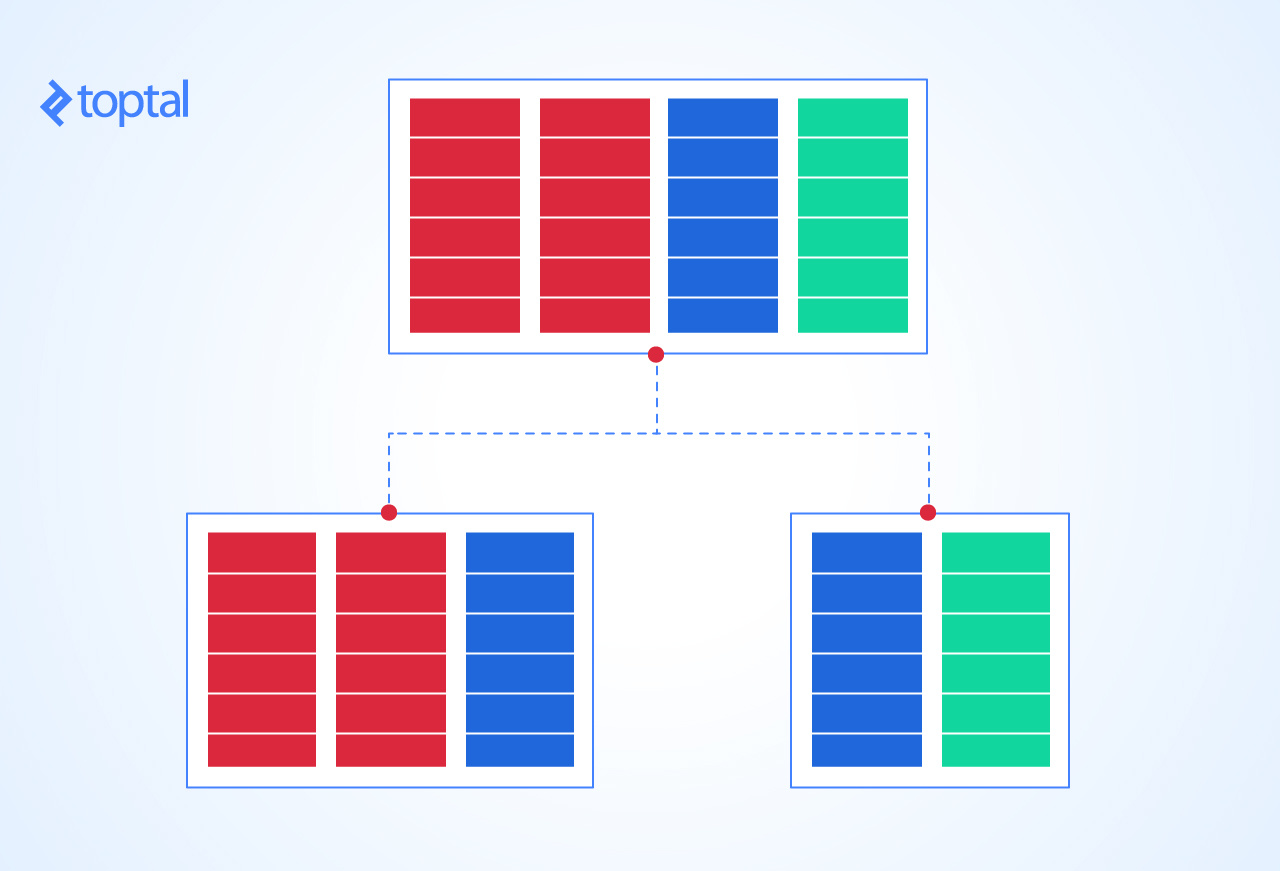
In spite of this, we are often faced with databases that were designed on the fly without following the most basic rules of normalization. We have to be clear on that: Every database should, at least, be normalized to third normal form, since it is the layout that will best represent your entities, and whose performance will be best balanced between querying and inserting-updating-deleting records.
If you stumble with tables that do not comply with 3NF, 2NF, or even 1NF, consider redesigning these tables. The effort you invest in doing so will pay off in the very short term.
Bad Practice No. 3: Redundancy
Very related to the previous point, since one of the goals of normalization is to reduce it, redundancy is another bad practice that appears quite often.
Redundant fields and tables are a nightmare for
Typical bad effects of redundancy are an unnecessary increase of database size, data being prone to inconsistency, and decreases in the efficiency of the database, but—more importantly—it may lead to data corruption.
Bad Practice No. 4: Bad Referential Integrity (Constraints)
Referential integrity is one of the most valuable tools that database engines provide to keep data quality at its best. If no constraints or very few constraints are implemented from the design stage, the data integrity will have to rely entirely on the business logic, making it susceptible to human error.
Bad Practice No. 5: Not Taking Advantage of DB Engine Features
When you are using a database engine (DBE), you have a powerful piece of software for your data handling tasks that will simplify software development and guarantee that information is always correct, safe, and usable. A DBE provides services like:
Views that provide a quick and efficient way to look at your data, typically de-normalizing it for query purposes without losing data correctness.
Indexes that help speed up queries on tables.
Aggregate functions that help analyze information without programming.
Transactions or blocks of data-altering sentences that are all executed and committed or
cancelled (rolled back) if something unexpected occurs, thus keeping information in a perpetually correct state.Locks that keep data safe and correct while transactions are being executed.
Stored procedures that provide programming features to allow complex data management tasks.
Functions that allow sophisticated calculations and data transformations.
Constraints that help guarantee data correctness and avoid errors.
Triggers that help automate actions when events occur on the data.
Command optimizer (execution planner) that runs under the hood, ensuring that every sentence is executed at its best and keeping the execution plans for future occasions. This is one of the best reasons to use views, stored procedures, and
functions, since their execution plans are kept permanently in the DBE.
Bad Practice No. 6: Composite Primary Keys
This is sort of a controversial
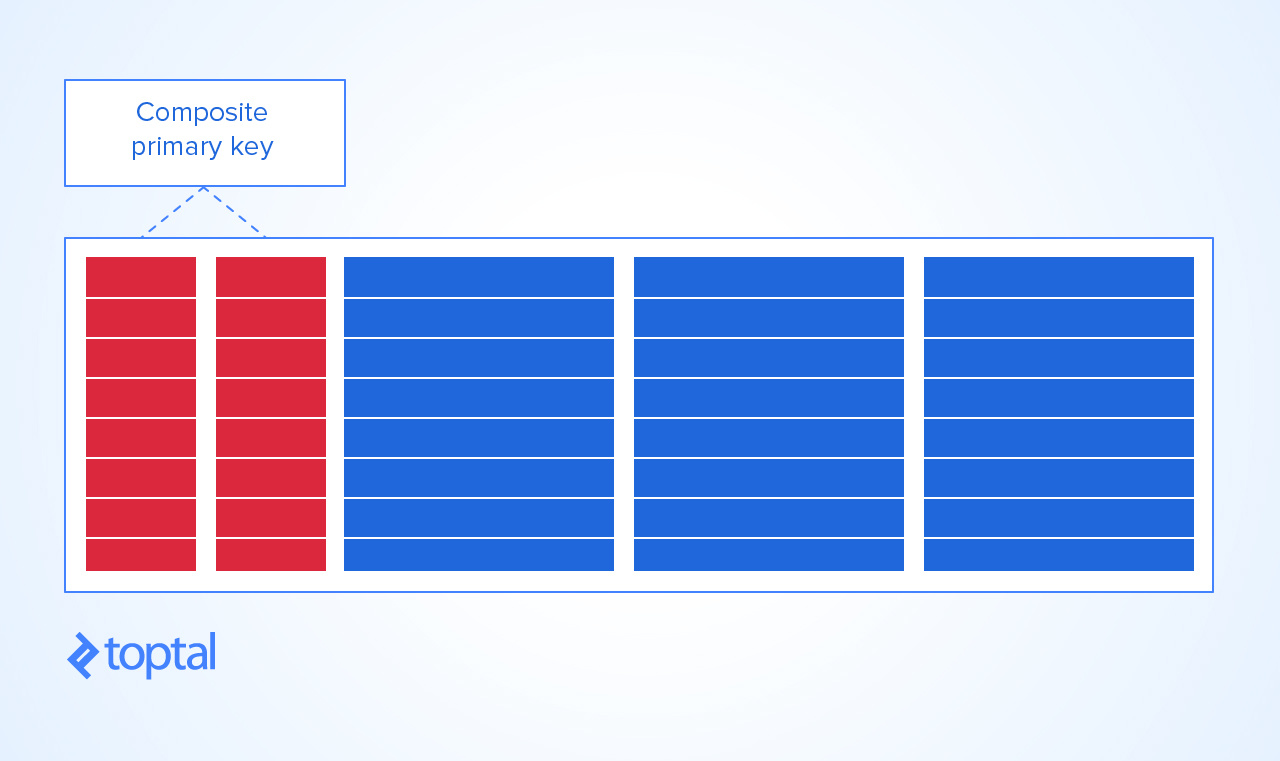
However, this is just a convention and, of course, DBEs allow the definition of composite primary keys, which many designers think are unavoidable. Therefore, as with redundancy, composite primary keys are a design decision.
Beware, though, if your table with a composite primary key is expected to have millions of rows, the index controlling the composite key can grow up to a point where CRUD operation performance is very degraded. In that case, it is a lot better to use a simple integer ID primary key whose index will be compact enough and establish the necessary DBE constraints to maintain uniqueness.
Bad Practice No. 7: Poor Indexing
Sometimes, you will have a table that you need to query by many columns. As the table grows, you will notice that the SELECTs on these columns slow down. If the table is big enough, you will think, logically, to create an index on each column that you use to access this table only to find almost immediately that the performance of SELECTs improves but INSERTs, UPDATEs, and DELETEs drop. This, of course, is due to the fact that indexes have to be kept synchronized with the table, which means massive overhead for the DBE. This is a typical case of
On the other hand, having a table with no index on columns that are used to query it will, as we all know, lead to poor performance on SELECTs.
Also, index efficiency depends sometimes on the column type; indexes on INT columns show the best possible performance, but indexes on VARCHAR, DATE or DECIMAL (if it ever makes sense) are not as efficient. This consideration can even lead to redesigning tables that need to be accessed with the best possible efficiency.
Therefore, indexing is always a delicate decision, as too much indexing can be as bad as too little and because the data type of the columns to index on
Bad Practice No. 8: Poor Naming Conventions
This is something that programmers always struggle with when facing an existing database: understanding what information is stored in it by the names of tables and columns because, often, there is no other way.
The table name must describe what entity it holds, and each column name must describe what piece of information it represents. This is easy, but it starts to be complicated when tables have to relate to each other. Names start to become messy and, worse, if there are confusing naming conventions with illogical norms (like, for instance, column name must be 8 characters or less). The final consequence is that the database becomes unreadable.
Therefore, a naming convention is always necessary if the database is expected to last and evolve with the application it supports, and here are some guidelines to establish a succinct, simple, and readable one:
No limitations on table or column name size. It is better to have a descriptive name than an acronym that no one remembers or understands.
Names that are equal have the same meaning. Avoid having fields that have the same name but with different types or meanings; this will be confusing sooner or later.
Unless necessary, don’t be redundant. For example, in the table Item, there is no need to have columns like ItemName, PriceOfItem, or similar names; Name and Price are enough.
Beware of DBE reserved words. If a column is to be called Index, which is a SQL reserved word, try to use a different one like IndexNumber.
If sticking to the simple primary key rule (single integer
auto generated ), name it Id in every table.If joining to another table, define the necessary foreign key as an integer, named Id followed by the name of the joined table (e.g.,
IdItem ).If naming constraints, use a prefix describing the constraint (e.g., PK or FK), followed by the name of the table or tables involved. Of course, using underscores (_) sparingly helps make things more readable.
To name indexes, use the prefix IDX followed by the table name and the column or columns of the index. Also, use UNIQUE as a prefix or suffix if the index is unique, and underscores where necessary.
There are many database naming guidelines on the internet that will shine more light on this very important aspect of database design, but with these basic ones, you can at least get to a readable database. What is important here is not the size or the complexity of your naming guidelines but your consistency in following them!
11
This blog is listed under
Data & Information Management
Community
Related Posts:
Post a Comment
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!







