Python Multithreading and Multiprocessing Tutorial
Published on 24 May 18
 Michelle
Michelle1
0
Discussions criticizing Python often talk about how it is difficult to use Python for multithreaded work, pointing fingers at what is known as the global interpreter lock (affectionately referred to as the GIL) that prevents multiple threads of Python code from running simultaneously. Due to this, the Python multithreading module doesn’t quite behave the way you would expect it to if you’re not a Python developer and you are coming from other languages such as C++ or Java. It must be made clear that one can still write code in Python that runs concurrently or in parallel and make a stark difference in resulting performance, as long as certain things are taken into consideration. If you haven’t read it yet, I suggest you take a look at Eqbal Quran’s article on concurrency and parallelism in Ruby here on the Toptal Engineering Blog.
In this Python concurrency tutorial, we will write a small Python script to download the top popular images from Imgur. We will start with a version that downloads images sequentially, or one at a time. As a prerequisite, you will have to register an application on Imgur. If you do not have an Imgur account already, please create one first.
The scripts in this tutorial have been tested with Python 3.6.4. With some changes, they should also run with Python 2—urllib is what has changed the most between these two versions of Python.
Getting Started with Python Multithreading
Let us start by creating a Python module, named download.py. This file will contain all the functions necessary to fetch the list of images and download them. We will split these functionalities into three separate functions:
get_linksdownload_linksetup_download_dir
The third function, setup_download_dir, will be used to create a download destination directory if it doesn’t already exist.
Imgur’s API requires HTTP requests to bear the Authorization header with the client ID. You can find this client ID from the dashboard of the application that you have registered on Imgur, and the response will be JSON encoded. We can use Python’s standard JSON library to decode it. Downloading the image is an even simpler task, as all you have to do is fetch the image by its URL and write it to a file.
This is what the script looks like:
import jsonimport loggingimport osfrom pathlib import Pathfrom urllib.request import urlopen, Request logger = logging.getLogger(__name__) def get_links(client_id): headers = {'Authorization': 'Client-ID {}'.format(client_id)} req = Request('https://api.imgur.com/3/gallery/', headers=headers, method='GET') with urlopen(req) as resp: data = json.loads(resp.readall().decode('utf-8')) return map(lambda item: item['link'], data['data']) def download_link(directory, link): logger.info('Downloading %s', link) download_path = directory / os.path.basename(link) with urlopen(link) as image, download_path.open('wb') as f: f.write(image.readall()) def setup_download_dir(): download_dir = Path('images') if not download_dir.exists(): download_dir.mkdir() return download_dirNext, we will need to write a module that will use these functions to download the images, one by one. We will name this single.py. This will contain the main function of our first, naive version of the Imgur image downloader. The module will retrieve the Imgur client ID in the environment variable IMGUR_CLIENT_ID. It will invoke the setup_download_dir to create the download destination directory. Finally, it will fetch a list of images using the get_links function, filter out all GIF and album URLs, and then use download_link to download and save each of those images to the disk. Here is what single.py looks like:
import loggingimport osfrom time import time from download import setup_download_dir, get_links, download_link logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')logging.getLogger('requests').setLevel(logging.CRITICAL)logger = logging.getLogger(__name__) def main(): ts = time() client_id = os.getenv('IMGUR_CLIENT_ID') if not client_id: raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!") download_dir = setup_download_dir() links = [l for l in get_links(client_id) if l.endswith('.jpg')] for link in links: download_link(download_dir, link) print('Took {}s'.format(time() - ts)) if __name__ == '__main__': main()On my laptop, this script took 19.4 seconds to download 91 images. Please do note that these numbers may vary based on the network you are on. 19.4 seconds isn’t terribly long, but what if we wanted to download more pictures? Perhaps 900 images, instead of 90. With an average of 0.2 seconds per picture, 900 images would take approximately 3 minutes. For 9000 pictures it would take 30 minutes. The good news is that by introducing concurrency or parallelism, we can speed this up dramatically.
All subsequent code examples will only show import statements that are new and specific to those examples. For convenience, all of these Python scripts can be found in this GitHub repository.
Using Threads for Concurrency and Parallelism
Threading is one of the most well-known approaches to attaining Python concurrency and parallelism. Threading is a feature usually provided by the operating system. Threads are lighter than processes, and share the same memory space.
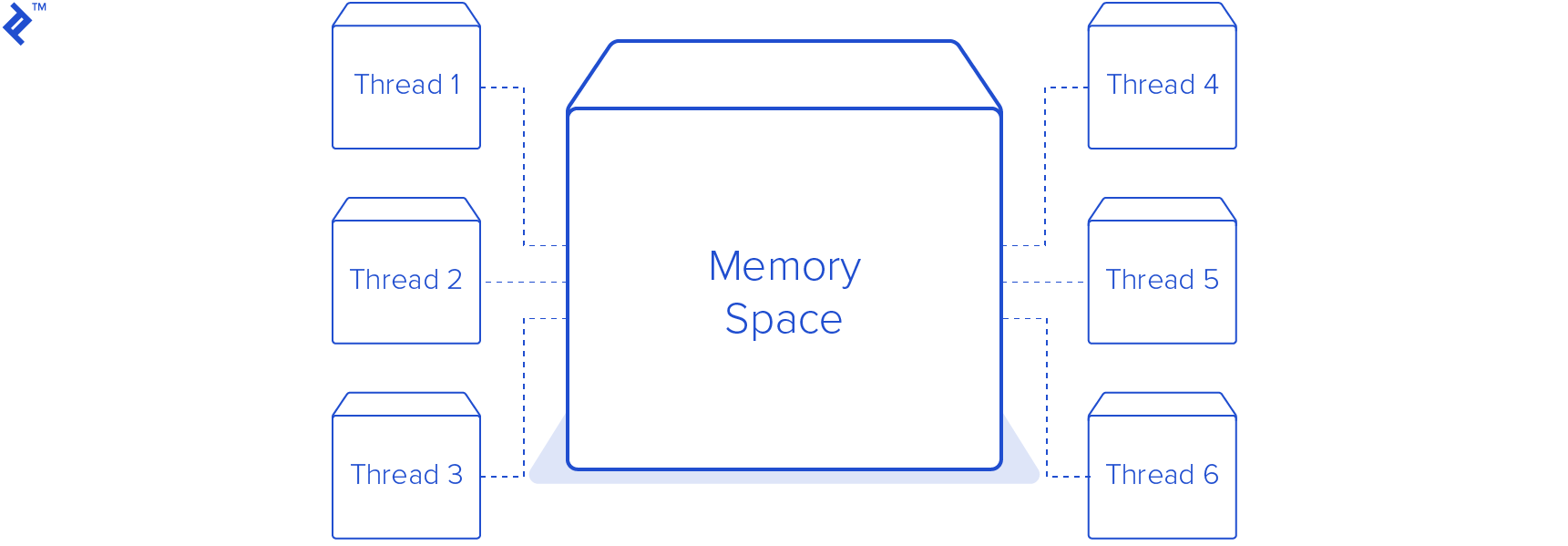
In our Python threading tutorial, we will write a new module to replace single.py. This module will create a pool of eight threads, making a total of nine threads including the main thread. I chose eight worker threads because my computer has eight CPU cores and one worker thread per core seemed a good number for how many threads to run at once. In practice, this number is chosen much more carefully based on other factors, such as other applications and services running on the same machine.
This is almost the same as the previous one, with the exception that we now have a new class, DownloadWorker, which is a descendent of the Python Thread class. The run method has been overridden, which runs an infinite loop. On every iteration, it calls self.queue.get() to try and fetch a URL to from a thread-safe queue. It blocks until there is an item in the queue for the worker to process. Once the worker receives an item from the queue, it then calls the same download_link method that was used in the previous script to download the image to the images directory. After the download is finished, the worker signals the queue that that task is done. This is very important, because the Queue keeps track of how many tasks were enqueued. The call to queue.join() would block the main thread forever if the workers did not signal that they completed a task.
from queue import Queuefrom threading import Threadclass DownloadWorker(Thread): def __init__(self, queue): Thread.__init__(self) self.queue = queue def run(self): while True: # Get the work from the queue and expand the tuple directory, link = self.queue.get() download_link(directory, link)def main(): self.queue.task_done() ts = time() client_id = os.getenv('IMGUR_CLIENT_ID') if not client_id: raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!") download_dir = setup_download_dir() links = [l for l in get_links(client_id) if l.endswith('.jpg')] # Create a queue to communicate with the worker threads queue = Queue() # Create 8 worker threads for x in range(8): worker = DownloadWorker(queue) # Setting daemon to True will let the main thread exit even though the workers are blocking worker.daemon = True worker.start() # Put the tasks into the queue as a tuple for link in links: logger.info('Queueing {}'.format(link)) queue.put((download_dir, link)) # Causes the main thread to wait for the queue to finish processing all the tasks queue.join() print('Took {}'.format(time() - ts))Running this Python threading example script on the same machine used earlier results in a download time of 4.1 seconds! That’s 4.7 times faster than the previous example. While this is much faster, it is worth mentioning that only one thread was executing at a time throughout this process due to the GIL. Therefore, this code is concurrent but not parallel. The reason it is still faster is because this is an IO bound task. The processor is hardly breaking a sweat while downloading these images, and the majority of the time is spent waiting for the network. This is why Python multithreading can provide a large speed increase. The processor can switch between the threads whenever one of them is ready to do some work. Using the threading module in Python or any other interpreted language with a GIL can actually result in reduced performance. If your code is performing a CPU bound task, such as decompressing gzip files, using the threading module will result in a slower execution time. For CPU bound tasks and truly parallel execution, we can use the multiprocessing module.
While the de facto reference Python implementation—CPython–has a GIL, this is not true of all Python implementations. For example, IronPython, a Python implementation using the .NET framework, does not have a GIL, and neither does Jython, the Java-based implementation. You can find a list of working Python implementations here.
This blog is listed under
Open Source
and Development & Implementations
Community
Related Posts:
Python
Multithreading
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!








Well, this is my first visit to your blog! Your blog provided us valuable information .You have done a marvelous job - slope