esProc Helps Process Structured Texts in Java -Non-Single Row Records
Published on 18 November 14
 Machine
Machine0
0
esProc can help Java deal with various computations in processing structured texts. But in the case of non-single row records, it is necessary to preprocess the data before esProc can perform computations on it.
Let’s look at this through an example. The text file Social.txt is the access records of a website, in which every three rows corresponds to a record. The records should be rearranged first before other computations can be performed. They should be imported in the form of(UserID, Time, IP, URL and Location)for future use or for storing in files. Note that the column separator should be tab and row separator should be the carriage return. The first rows of data are as follows:
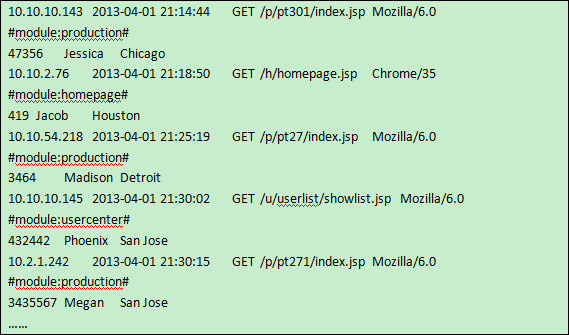
For each record of three rows in the text file, the first row of data of IP, URL and Time, and the third row of data of UserID and Location are useful, but the second row of data is useless. Thus the first record, for example, should be (UserID, Time, IP, URL, Location)=(47356, 2013-04-01 21:14:44, 10.10.10.143, /p/pt301/index.jsp, Chicago). The steps of pre-process of the records are as follows:
Code in esProc:
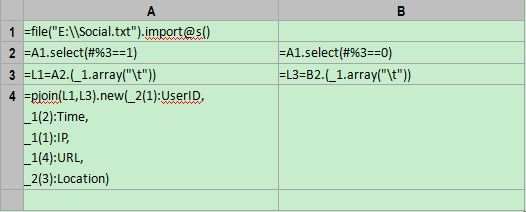
Code interpretation:
A1:file("E:\\Social.txt").import@t()
This line of code is to import the whole text file to the table sequence object, as shown below: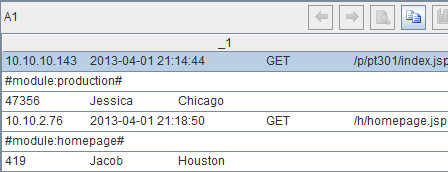
As can be seen from above, A1 has only one column with _1being the default name. Each row of the text file corresponds to a piece of data in _1.
A2:A1.select(#%3==1)
This line of code is to select the first of the three rows by the row numbers, such as the 1st, 4th, 7th and 10th rows. The sign # represents row number and the sign % represents getting the remainder. select function can make query on the table sequence by field name or by row numbers. The result after the code is executed is as follows: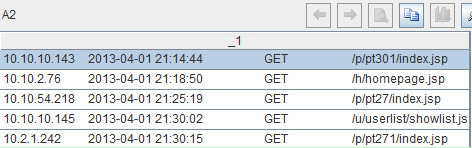
B2:A1.select(#%3==0)
Similarly, this line of code is to select the third of the three rows, such as the 3rd, 6th, 9th and 12th rows. The result is as follows: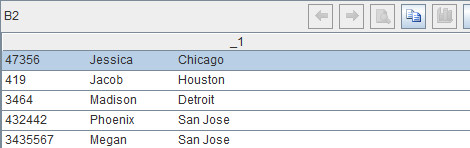
After the three steps, the first and third rows of each record have been stored respectively in table sequence A2 and B2. The two sequences have the same number of rows with corresponding row numbers. But at this point, the records haven’t been split yet.
L1=A2.(_1.array("\t"))
This is to split the first row of each record to form a string sequence. The sequence of string sequences will be named L1. \t means that tab is used as the separator. The result is as follows: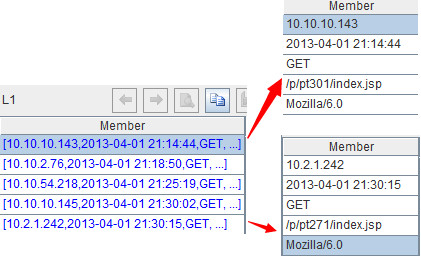
As shown in the above figure, each member of L1 corresponds to a string sequence. Click the hyperlinks in blue and members of each string sequence will be shown. The third row of each record will be processed in the same way. The code for this is =L3=B2.(_1.array("\t"))and the resulting sequence of string sequences will be named L3, as shown below:
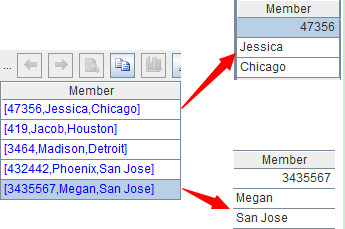
Now we’ll join the needed fields in L1 and L3 together to form a new table sequence:
pjoin(L1,L3).new(_2(1):UserID, _1(2):Time, _1(1):IP, _1(4):URL, _2(3):Location)
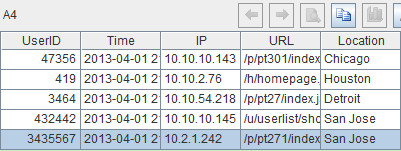
The result is as follows:
pjoin function is used to concatenate L1 and L3 according to the row numbers. After the concatenation L1’s name is _1 and L3’s name is _2 by default. new function is used to generate a new table sequence. _2(1):UserID represents getting the first member of each member in L3, joining them together and naming the new sequence and field UserID. In the same way, we can know the meaning of other parameters of the new function.
A4 shows the selected useful records. To store these records in a file, we can use the following code:=file("E: \\result.txt").export@t(A4), in which option @t means storing the field name in the first row of the file.
Or we can perform structured data computing on A4 as we did before. That is, grouping and summarizing the data by regions, computing the page views of each region, selecting those regions where the page views are above a certain number (say a million) and then passing the result to JDBC. The code for the computation is as follows:

=A4.groups(Location;count(~):pv)
This line of code is to group and summarize the data by regions and compute the number of page views of each region.
=A5.select(pv>=@arg) //@arg is an input parameter,like 1000000。
This line of code is to filter data by the number of page views and get the regions where the page views are above a certain number.
Tips: groups function can group and summarize multiple fields; select function can perform filtering according to multiple conditions.
result A5,
This line of code is to pass A5 to JDBC to be called by Java program.
In the following code, the esProc script is called by Java through JDBC.
//Create a connection using esProcjdbc
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//Call esProc script whose name is test
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call test(?)");
//Set the parameters. Assume the number of page views is above 1,000,000, but actually the value should be a variable in JAVA.
st.setObject(1,"1000000 ")//
st.execute();//Execute esProc stored procedure
ResultSet set = st.getResultSet(); //Get the result set
Sometimes a file featuring non-single row records has too many bytes to be wholly processed in the memory. To process this kind of files in Java, we have to import the data while computing it and storing the result in contemporary files, which makes the code rather complicated. But with the cursor object in esProc, these big files can be cleverly processed segmentally.
Big files processing in esProc:
First develop the main program main.dfx:
In the above code, pcursor calls a subprogram to return the cursor generated by the real records. A2 and A3 only execute the grouping, summarizing and filtering. Note that the computed result of A1 is cursors instead of in-memory data. Only while groups function is executed will the cursors be imported segmentally to the memory automatically and computed.
The subprogram sub.dfx is to process the file by loop. 3*N rows will be imported each time and N records are created and returned. pcursor will receive the computed result of each batch of data in order and transform it to a cursor. Note that the value of N should be kept in an appropriate range in case of a memory overflow if it is too big or a poor performance if it is too small. The detailed code is as follows:
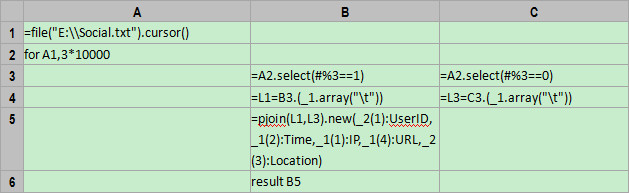
A1: =file("E:\\Social.txt").cursor()
Similar to the usage of import function, the cursor function in the above code is used to open file cursors. As it won’t really read the data to the memory, it can be used in processing big files.
A2-C6:Process the file by loop. for A1,3*10000 represents importing 30,000 rows data to the memory at a time. As the imported data is the same as that imported from small files, the code is also written in a same way.
This blog is listed under
Development & Implementations
and Data & Information Management
Community
Related Posts:
Java
Structured Data
Post a Comment
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!







