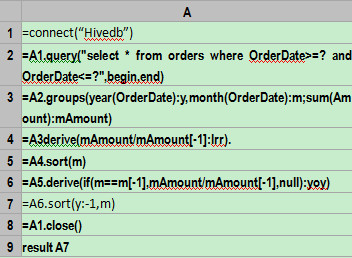
It is easy for Java to connect to Hive using JDBC. But the computational ability of Hive is less than that of SQL in other databases. So to deal with uncommon computations, data should be retrieved before further operation is performed using Java. Thus the code for will be complicated.
But if esProc is used to help with the Java programming, the complicated operation as a result of using Hive in Java will become simpler. The following example will show how esProc works with Java in detail. orders is a table in Hive containing the detailed data of sales orders. Now it is required to compute the year-on-year comparison and link relative ratio. The data is as follows:
ORDERID CLIENT SELLERID AMOUNT ORDERDATE
1 UJRNP 17 392 2008/11/2 15:28
2 SJCH 6 4802 2008/11/9 15:28
3 UJRNP 16 13500 2008/11/5 15:28
4 PWQ 9 26100 2008/11/8 15:28
5 PWQ 11 4410 2008/11/12 15:28
6 HANAR 18 6174 2008/11/7 15:28
7 EGU 2 17800 2008/11/6 15:28
8 VILJX 7 2156 2008/11/9 15:28
9 JAYB 14 17400 2008/11/12 15:28
10 JAXE 19 19200 2008/11/12 15:28
11 SJCH 7 13700 2008/11/10 15:28
12 QUICK 11 21200 2008/11/13 15:28
13 HL 12 21400 2008/11/21 15:28
14 JAYB 1 7644 2008/11/16 15:28
15 MIP 16 3234 2008/11/19 15:28
…
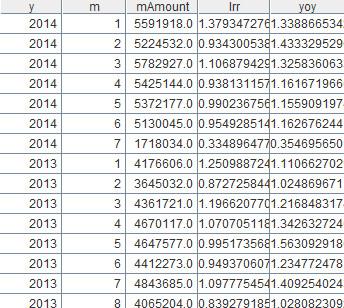
Link relative ratio refers to comparison between the current data and data of the previous period, using month as the time interval. For example, divide the sales figure in April by that in March and we get the link relative ratio of April. Year-on-year comparison is the comparison between the current data and data of the corresponding period of the previous year, which means, for example, dividing the sales figure of April 2014 by that of April 2013. Since Hive provides no window functions, it cannot complete the computation unless using nested SQL. But Hive supports very poor subquery and usually the computation should be performed outside of the database. With esProc, however, the computation can be realized easily. The code is as follows:  Raqsoft
Raqsoft