Big Data, Data Science Masters Program

Intellipaat
Course Summary
Our Big Data, Data Science Masters program lets you gain proficiency in Big Data & Data Science. You will work on real world projects in Hadoop development, administration, testing, analyst, HDFS, MapReduce, Hive, Pig, Spark, Storm, Scala, Data analytics, Splunk, NoSQL databases, and more. In this program you will cover 21 courses and 48 industry based projects
-
+
Course Description
Intellipaat’s Big Data Data Science masters program will provide you in-depth knowledge on designing, developing and deploying data science and Big data application in real world along with performance tuning of the application. This course will make you Big Data & Data Science Architect and by the end of the course you will have expertise on Hadoop Developer, Administration, testing and analysis Modules, working with real-time analytics, statistical computing, parsing machine-generated data, creating NoSQL applications and finally the domain of deep Learning in artificial intelligence. This program is specially designed by Industry experts and you will get 21 courses with 48 Industry based projectsAbout Course
List of courses included:
Online Instructor-Led Courses :- Hadoop Developer
- Hadoop Administration
- Hadoop Analyst
- Hadoop Testing
- Apache Spark & Scala
- Storm
- Data Science with R
- Data Science with SAS
- Splunk Developer and Administration
- Deep learning
- Python
- Tableau Desktop 10
- MongoDB
- HBase
- Cassandra
- CouchBase
- Mahout
- Solr
- Linux
- Java
- Kafka
What you will learn in this masters program?
- Introduction to Hadoop
- Detailed MapReduce, and HDFS
- Hive, Pig, Sqoop, Flume, HBase
- Real-time analytics with Spark
- Prediction & analysis through clustering
- Deploying recommender system
- SAS advanced analytics & R programming
- Linear and logistic regression
- Designing and Developing NoSQL applications
- Mastering Artificial Intelligence Algorithms and their practical use cases
Who should take this training?
- Big Data and Data Science professionals, Software developers
- Business Intelligence professionals, Information architects, Project Managers
- Those looking to make a career in Big Data, Data Science
What are the prerequisites for taking this Training Course?
There are no prerequisites for taking this training program.Why should you take this training program?
- Global Big Data market to reach $122B in revenue by 2025 – Frost & Sullivan
- The US alone could face a shortage of 1.4 -1.9 million Big Data Analysts by 2018 – Mckinsey
This Intellipaat training program has been created keeping in mind the needs of the industry. You will gain mastery in the complete domain of Data Science, Hadoop ecosystem to take on various roles and responsibilities. So you will be better prepared to take on challenging roles in the Big Data and Data Science domains at top-notch salaries.How Big is Big Data – Find out and Get Ahead!
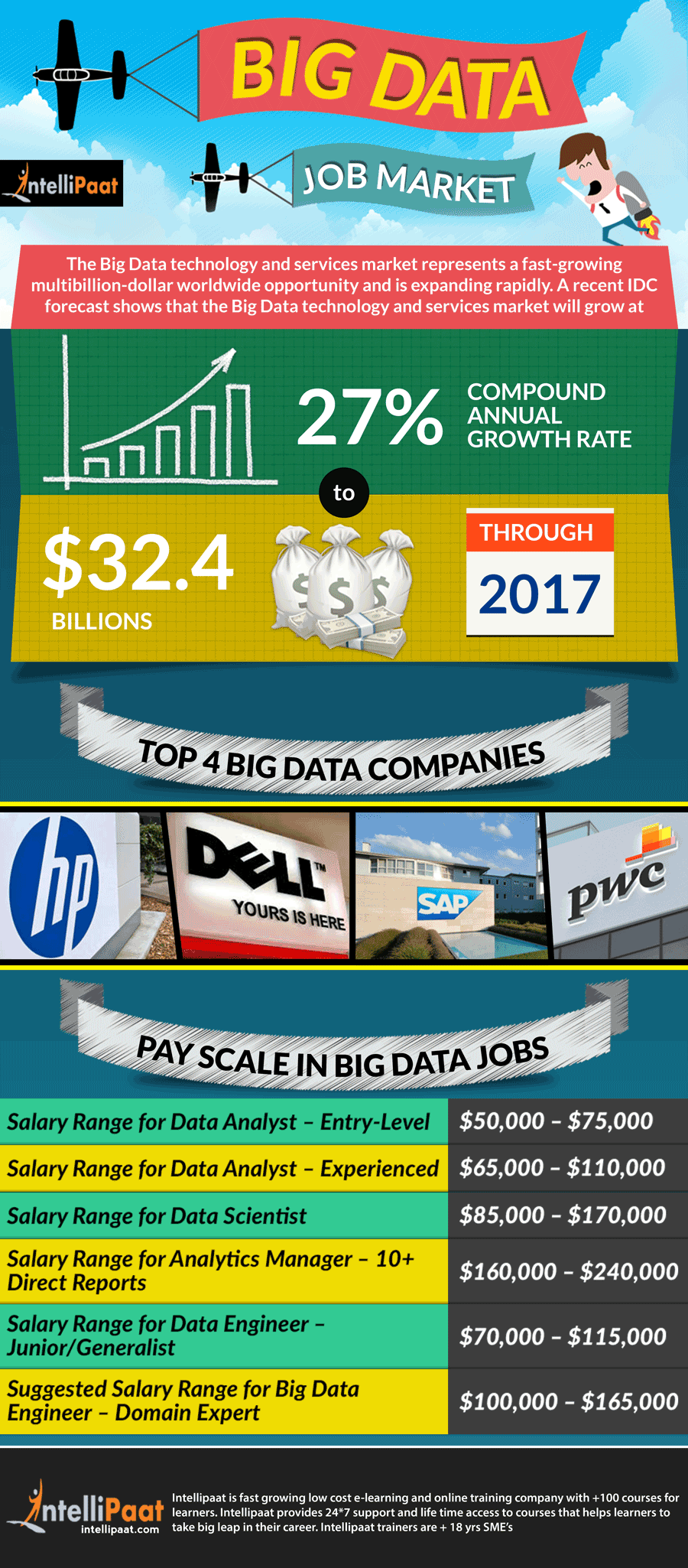
-
+
Course Syllabus
Big Data Hadoop Course Content
Hadoop Installation & setupHadoop 2.x Cluster Architecture, Federation and High Availability, A Typical Production Cluster setup, Hadoop Cluster Modes, Common Hadoop Shell Commands, Hadoop 2.x Configuration Files, Cloudera Single node cluster, Hive, Pig, Sqoop, Flume, Scala and Spark.Introduction to Big Data Hadoop. Understanding HDFS & MapreduceIntroducing Big Data & Hadoop, what is Big Data and where does Hadoop fits in, two important Hadoop ecosystem componentsnamely Map Reduce and HDFS, in-depth Hadoop Distributed File System – Replications, Block Size, Secondary Name node, High Availability, in-depth YARN – Resource Manager, Node Manager.Hands-on Exercise – Working with HDFS, replicating the data, determining block size, familiarizing with Namenode and Datanode.
Deep Dive in MapreduceDetailed understanding of the working of MapReduce, the mapping and reducing process, the working of Driver, Combiners, Partitioners, Input Formats, Output Formats, Shuffle and SorHands-on Exercise – The detailed methodology for writing the Word Count Program in MapReduce, writing custom partitioner, MapReduce with Combiner, Local Job Runner Mode, Unit Test, ToolRunner, MapSide Join, Reduce Side Join, Using Counters, Joining two datasets using Map-Side Join &Reduce-Side JoinIntroduction to HiveIntroducing Hadoop Hive, detailed architecture of Hive, comparing Hive with Pig and RDBMS, working with Hive Query Language, creation of database, table, Group by and other clauses, the various types of Hive tables, Hcatalog, storing the Hive Results, Hive partitioning and Buckets.Hands-on Exercise – Creating of Hive database, how to drop database, changing the database, creating of Hive table, loading of data, dropping the table and altering it, writing hive queries to pull data using filter conditions, group by clauses, partitioning Hive tablesAdvance Hive & ImpalaThe indexing in Hive, the Map side Join in Hive, working with complex data types, the Hive User-defined Functions, Introduction to Impala, comparing Hive with Impala, the detailed architecture of ImpalaHands-on Exercise – Working with Hive queries, writing indexes, joining table, deploying external table, sequence table and storing data in another table.Introduction to PigApache Pig introduction, its various features, the various data types and schema in Hive, the available functions in Pig, Hive Bags, Tuples and Fields.Hands-on Exercise – Working with Pig in MapReduce and local mode, loading of data, limiting data to 4 rows, storing the data into file, working with Group By,Filter By,Distinct,Cross,Split in Hive.Flume, Sqoop & HBaseIntroduction to Apache Sqoop, Sqoop overview, basic imports and exports, how to improve Sqoop performance, the limitation of Sqoop, introduction to Flume and its Architecture, introduction to HBase, the CAP theorem.Hands-on Exercise – Working with Flume to generating of Sequence Number and consuming it, using the Flume Agent to consume the Twitter data, using AVRO to create Hive Table, AVRO with Pig, creating Table in HBase, deploying Disable, Scan and Enable Table.Writing Spark Applications using ScalaUsing Scala for writing Apache Spark applications, detailed study of Scala, the need for Scala, the concept of object oriented programing, executing the Scala code, the various classes in Scala like Getters,Setters, Constructors, Abstract ,Extending Objects, Overriding Methods, the Java and Scala interoperability, the concept of functional programming and anonymous functions, Bobsrockets package, comparing the mutable and immutable collections.Hands-on Exercise – Writing Spark application using Scala, understanding the robustness of Scala for Spark real-time analytics operation.Spark frameworkDetailed Apache Spark, its various features, comparing with Hadoop, the various Spark components, combining HDFS with Spark, Scalding, introduction to Scala, importance of Scala and RDD.Hands-on Exercise – The Resilient Distributed Dataset in Spark and how it helps to speed up big data processing.
RDD in SparkThe RDD operation in Spark, the Spark transformations, actions, data loading, comparing with MapReduce, Key Value Pair.Hands-on Exercise – How to deploy RDD with HDFS, using the in-memory dataset, using file for RDD, how to define the base RDD from external file, deploying RDD via transformation, using the Map and Reduce functions, working on word count and count log severity.
Data Frames and Spark SQLThe detailed Spark SQL, the significance of SQL in Spark for working with structured data processing, Spark SQL JSON support, working with XML data, and parquet files, creating HiveContext, writing Data Frame to Hive, reading of JDBC files, the importance of Data Frames in Spark, creating Data Frames, schema manual inferring, working with CSV files, reading of JDBC tables, converting from Data Frame to JDBC, the user-defined functions in Spark SQL, shared variable and accumulators, how to query and transform data in Data Frames, how Data Frame provides the benefits of both Spark RDD and Spark SQL, deploying Hive on Spark as the execution engine.Hands-on Exercise – Data querying and transformation using Data Frames, finding out the benefits of Data Frames over Spark SQL and Spark RDD.Machine Learning using Spark (Mlib)Different Algorithms, the concept of iterative algorithm in Spark, analyzing with Spark graph processing, introduction to K-Means and machine learning, various variables in Spark like shared variables, broadcast variables, learning about accumulators.Hands-on Exercise – Writing spark code using Mlib.
Spark StreamingIntroduction to Spark streaming, the architecture of Spark Streaming, working with the Spark streaming program, processing data using Spark streaming, requesting count and Dstream, multi-batch and sliding window operations and working with advanced data sources.Hands-on Exercise – Deploying Spark streaming for data in motion and checking the output is as per the requirement.
Hadoop Administration – Multi Node Cluster Setup using Amazon EC2Create a four node Hadoop cluster setup, running the MapReduce Jobs on the Hadoop cluster, successfully running the MapReduce code, working with the Cloudera Manager setup.Hands-on Exercise – The method to build a multi-node Hadoop cluster using an Amazon EC2 instance, working with the Cloudera Manager.
Hadoop Administration – Cluster ConfigurationThe overview of Hadoop configuration, the importance of Hadoop configuration file, the various parameters and values of configuration, the HDFS parameters and MapReduce parameters, setting up the Hadoop environment, the Include’ and Exclude configuration files, the administration and maintenance of Name node, Data node directory structures and files, File system image and Edit logHands-on Exercise – The method to do performance tuning of MapReduce program.
Hadoop Administration – Maintenance, Monitoring and TroubleshootingIntroduction to the Checkpoint Procedure, Name node failure and how to ensure the recovery procedure, Safe Mode, Metadata and Data backup, the various potential problems and solutions, what to look for, how to add and remove nodes.Hands-on Exercise – How to go about ensuring the MapReduce File system Recovery for various different scenarios, JMX monitoring of the Hadoop cluster, how to use the logs and stack traces for monitoring and troubleshooting, using the Job Scheduler for scheduling jobs in the same cluster, getting the MapReduce job submission flow, FIFO schedule, getting to know the Fair Scheduler and its configuration.
Securing Hadoop Cluster with Kerberos and other Advance topicsAdvanced Hadoop administration functions, using the Quorum Journal Manager, configuring the Hadoop federation and security, fundamentals of the Hadoop Platform Security, working with Kerberos authentication, configuring Kerberos on Hadoop cluster.Hands-on Exercise – Detailed procedure for configuring the Kerberos authentication with the Hadoop cluster and checking the results of the configuration.
ETL Connectivity with Hadoop EcosystemHow ETL tools work in Big data Industry, Introduction to ETL and Data warehousing. Working with prominent use cases of Big data in ETL industry, End to End ETL PoC showing big data integration with ETL tool.Hands-on Exercise – Connecting to HDFS from ETL tool and moving data from Local system to HDFS, Moving Data from DBMS to HDFS, Working with Hive with ETL Tool, Creating Map Reduce job in ETL tool
IBM Project Solution Discussion and Cloudera Certification Tips & TricksWorking towards the solution of the Hadoop IBM project solution, its problem statements and the possible solution outcomes, preparing for the Cloudera Certifications, points to focus for scoring the highest marks, tips for cracking Hadoop interview questions.Hands-on Exercise – The IBM project of a real-world high value Big Data Hadoop application and getting the right solution based on the criteria set by the IBM team.
Following topics will be available only in self-paced Mode.Hadoop Application TestingWhy testing is important, Unit testing, Integration testing, Performance testing, Diagnostics, Nightly QA test, Benchmark and end to end tests, Functional testing, Release certification testing, Security testing, Scalability Testing, Commissioning and Decommissioning of Data Nodes Testing, Reliability testing, Release testing
Roles and Responsibilities of Hadoop Testing ProfessionalUnderstanding the Requirement, preparation of the Testing Estimation, Test Cases, Test Data, Test bed creation, Test Execution, Defect Reporting, Defect Retest, Daily Status report delivery, Test completion, ETL testing at every stage (HDFS, HIVE, HBASE) while loading the input (logs/files/records etc) using sqoop/flume which includes but not limited to data verification, Reconciliation, User Authorization and Authentication testing (Groups, Users, Privileges etc), Report defects to the development team or manager and driving them to closure, Consolidate all the defects and create defect reports, Validating new feature and issues in Core Hadoop.
Framework called MR Unit for Testing of Map-Reduce ProgramsReport defects to the development team or manager and driving them to closure, Consolidate all the defects and create defect reports, Responsible for creating a testing Framework called MR Unit for testing of Map-Reduce programs.
Unit TestingAutomation testing using the OOZIE, Data validation using the query surge tool.
Test ExecutionTest plan for HDFS upgrade, Test automation and result
Test Plan Strategy and writing Test Cases for testing Hadoop ApplicationHow to test install and configure
Scala Course Content
Introduction of ScalaIntroducing Scala and deployment of Scala for Big Data applications and Apache Spark analytics.
Pattern MatchingThe importance of Scala, the concept of REPL (Read Evaluate Print Loop), deep dive into Scala pattern matching, type interface, higher order function, currying, traits, application space and Scala for data analysis.
Executing the Scala codeLearning about the Scala Interpreter, static object timer in Scala, testing String equality in Scala, Implicit classes in Scala, the concept of currying in Scala, various classes in Scala.
Classes concept in ScalaLearning about the Classes concept, understanding the constructor overloading, the various abstract classes, the hierarchy types in Scala, the concept of object equality, the val and var methods in Scala.
Case classes and pattern matchingUnderstanding Sealed traits, wild, constructor, tuple, variable pattern, and constant pattern.
Concepts of traits with exampleUnderstanding traits in Scala, the advantages of traits, linearization of traits, the Java equivalent and avoiding of boilerplate code.
Scala java InteroperabilityImplementation of traits in Scala and Java, handling of multiple traits extending.
Scala collectionsIntroduction to Scala collections, classification of collections, the difference between Iterator, and Iterable in Scala, example of list sequence in Scala.
Mutable collections vs. Immutable collectionsThe two types of collections in Scala, Mutable and Immutable collections, understanding lists and arrays in Scala, the list buffer and array buffer, Queue in Scala, double-ended queue Deque, Stacks, Sets, Maps, Tuples in Scala.
Use Case bobsrockets packageIntroduction to Scala packages and imports, the selective imports, the Scala test classes, introduction to JUnit test class, JUnit interface via JUnit 3 suite for Scala test, packaging of Scala applications in Directory Structure, example of Spark Split and Spark Scala.
Spark Course Content
Introduction to SparkIntroduction to Spark, how Spark overcomes the drawbacks of working MapReduce, understanding in-memory MapReduce, Spark Hadoop YARN, HDFS Revision, YARN Revision, the overview of Spark and how it is better Hadoop, deploying Spark without Hadoop.
Spark BasicsSpark installation guide, working with Spark Shell, the concept of Resilient Distributed Datasets (RDD), learning to do functional programming in Spark, the architecture of Spark.
Working with RDDs in SparkDeep dive into Spark RDDs, the RDD general operations, a read-only partitioned collection of records, using the concept of RDD for faster and efficient data processing.
Aggregating Data with Pair RDDsUnderstanding the concept of Key-Value pair in RDDs, learning how Spark makes MapReduce operations faster, various operations of RDD.
Writing and Deploying Spark ApplicationsComparing the Spark applications with Spark Shell, creating a Spark application using Scala or Java, deploying a Spark application, the web user interface of Spark application, a real world example of Spark and configuring of Spark.
Parallel ProcessingLearning about Spark parallel processing, deploying on a cluster, introduction to Spark partitions, file-based partitioning of RDDs, understanding of HDFS and data locality, mastering the technique of parallel operations.
Spark RDD PersistenceUnderstanding the RDD persistence overview, distributed persistence, RDD lineage
Basic Spark StreamingUnderstanding the Spark streaming, creating a Spark stream application, processing of Spark stream, streaming request count and DStreams.
Advanced Spark StreamingIntroduction to Spark multi-batch operations, state operations, sliding window operations and advanced data sources.
Common Patterns in Spark Data ProcessingLearning about the Spark common use cases, the concept of iterative algorithm in Spark, analyzing with Spark graph processing, introduction to K-Means and machine learning.
Improving Spark PerformanceIntroduction to various variables in Spark like shared variables, broadcast variables, learning about accumulators, the common performance issues and troubleshooting the performance problems.
Spark SQL and Data FramesLearning about Spark SQL, the context of SQL in Spark for providing structured data processing, understanding the Data Frames in Spark, learning to query and transform data in Data Frames, how Data Frame provides the benefit of both Spark RDD and Spark SQL, deploying Hive on Spark as the execution engine.
Scheduling/ PartitioningLearning about the scheduling and partitioning in Spark, scheduling within and around applications, static partitioning, dynamic sharing, fair scheduling, Spark master high availability, standby Masters with Zookeeper, Single Node Recovery With Local File System, High Order Functions.
Capacity planning in SparkUnderstanding how to design capacity planning in Spark, creation of Maps, Transformations, the concept of concurrency in Java and Scala.
Log analysisUnderstanding about log analysis with Spark, first log analyzers in Spark, working with various buffers like array, compact and protocol buffer.
Apache Storm Course Content
Understanding Architecture of StormBig Data characteristics, understanding Hadoop distributed computing, the Bayesian Law, deploying Storm for real time analytics, the Apache Storm features, comparing Storm with Hadoop, Storm execution, learning about Tuple, Spout, Bolt.
Installation of Apache stormInstalling the Apache Storm, various types of run modes of Storm.
Introduction to Apache StormUnderstanding Apache Storm and the data model.
Apache Kafka InstallationInstallation of Apache Kakfa and its configuration.
Apache Storm AdvancedUnderstanding of advanced Storm topics like Spouts, Bolts, Stream Groupings, Topology and its Life cycle, learning about Guaranteed Message Processing.
Storm TopologyVarious Grouping types in Storm, reliable and unreliable messages, Bolt structure and life cycle, understanding Trident topology for failure handling, process, Call Log Analysis Topology for analyzing call logs for calls made from one number to another.
Overview of TridentUnderstanding of Trident Spouts and its different types, the various Trident Spout interface and components, familiarizing with Trident Filter, Aggregator and Functions, a practical and hands-on use case on solving call log problem using Storm Trident.
Storm Components & classesVarious components, classes and interfaces in storm like – Base Rich Bolt Class, i RichBolt Interface, i RichSpout Interface, Base Rich Spout class and the various methodology of working with them.
Cassandra IntroductionUnderstanding Cassandra, its core concepts, its strengths and deployment.
Boot StrippingTwitter Boot Stripping, detailed understanding of Boot Stripping, concepts of Storm, Storm Development Environment.
Data Science Course Content
Introduction to Data Science and Statistical AnalyticsIntroduction to Data Science, Use cases, Need of Business Analytics, Data Science Life Cycle, Different tools available for Data ScienceIntroduction to RInstalling R and R-Studio, R packages, R Operators, if statements and loops (for, while, repeat, break, next), switch caseData Exploration, Data Wrangling and R Data StructureImporting and Exporting data from external source, Data exploratory analysis, R Data Structure (Vector, Scalar, Matrices, Array, Data frame, List), Functions, Apply FunctionsData VisualizationBar Graph (Simple, Grouped, Stacked), Histogram, Pi Chart, Line Chart, Box (Whisker) Plot, Scatter Plot, CorrelogramIntroduction to StatisticsTerminologies of Statistics ,Measures of Centers, Measures of Spread, Probability, Normal Distribution, Binary Distribution, Hypothesis Testing, Chi Square Test, ANOVAPredictive Modeling – 1 ( Linear Regression)Supervised Learning – Linear Regression ,Bivariate Regression, Multiple Regression Analysis, Correlation( Positive, negative and neutral), Industrial Case Study, Machine Learning Use-Cases, Machine Learning Process Flow, Machine Learning CategoriesPredictive Modeling – 2 ( Logistic Regression)Logistic RegressionDecision TreesWhat is Classification and its use cases?, What is Decision Tree?, Algorithm for Decision Tree Induction, Creating a Perfect Decision Tree, Confusion MatrixRandom ForestRandom Forest, What is Naive Bayes?Unsupervised learningWhat is Clustering & its Use Cases?, What is K-means Clustering?, What is Canopy Clustering?, What is Hierarchical Clustering?Association Analysis and Recommendation engineMarket Basket Analysis (MBA), Association Rules, Apriori Algorithm for MBA, Introduction of Recommendation Engine, Types of Recommendation – User-Based and Item-Based, Recommendation Use-caseSentiment AnalysisIntroduction to Text Mining, Introduction to Sentiment, Setting up API bridge, between R and Tweeter Account, Extracting Tweet from Tweeter Acc, Scoring the tweetTime SeriesWhat is Time Series data?, Time Series variables, Different components of Time Series data, Visualize the data to identify Time Series Components, Implement ARIMA model for forecasting, Exponential smoothing models, Identifying different time series scenario based on which different Exponential Smoothing model can be applied, Implement respective ETS model for forecastingR Programming Course Content
Introduction to RR language for statistical programming, the various features of R, introduction to R Studio, the statistical packages, familiarity with different data types and functions, learning to deploy them in various scenarios, use SQL to apply ‘join’ function, components of R Studio like code editor, visualization and debugging tools, learn about R-bind.
R-PackagesR Functions, code compilation and data in well-defined format called R-Packages, learn about R-Package structure, Package metadata and testing, CRAN (Comprehensive R Archive Network), Vector creation and variables values assignment.
Sorting DataframeR functionality, Rep Function, generating Repeats, Sorting and generating Factor Levels, Transpose and Stack Function.
Matrices and VectorsIntroduction to matrix and vector in R, understanding the various functions like Merge, Strsplit, Matrix manipulation, rowSums, rowMeans, colMeans, colSums, sequencing, repetition, indexing and other functions.
Reading data from external filesUnderstanding subscripts in plots in R, how to obtain parts of vectors, using subscripts with arrays, as logical variables, with lists, understanding how to read data from external files.
Generating plotsGenerate plot in R, Graphs, Bar Plots, Line Plots, Histogram, components of Pie Chart.
Analysis of Variance (ANOVA)Understanding Analysis of Variance (ANOVA) statistical technique, working with Pie Charts, Histograms, deploying ANOVA with R, one way ANOVA, two way ANOVA.
K-means ClusteringK-Means Clustering for Cluster & Affinity Analysis, Cluster Algorithm, cohesive subset of items, solving clustering issues, working with large datasets, association rule mining affinity analysis for data mining and analysis and learning co-occurrence relationships.
Association Rule MiningIntroduction to Association Rule Mining, the various concepts of Association Rule Mining, various methods to predict relations between variables in large datasets, the algorithm and rules of Association Rule Mining, understanding single cardinality.
Regression in RUnderstanding what is Simple Linear Regression, the various equations of Line, Slope, Y-Intercept Regression Line, deploying analysis using Regression, the least square criterion, interpreting the results, standard error to estimate and measure of variation.
Analyzing Relationship with RegressionScatter Plots, Two variable Relationship, Simple Linear Regression analysis, Line of best fit
Advance RegressionDeep understanding of the measure of variation, the concept of co-efficient of determination, F-Test, the test statistic with an F-distribution, advanced regression in R, prediction linear regression.
Logistic RegressionLogistic Regression Mean, Logistic Regression in R.
Advance Logistic RegressionAdvanced logistic regression, understanding how to do prediction using logistic regression, ensuring the model is accurate, understanding sensitivity and specificity, confusion matrix, what is ROC, a graphical plot illustrating binary classifier system, ROC curve in R for determining sensitivity/specificity trade-offs for a binary classifier.
Receiver Operating Characteristic (ROC)Detailed understanding of ROC, area under ROC Curve, converting the variable, data set partitioning, understanding how to check for multicollinearlity, how two or more variables are highly correlated, building of model, advanced data set partitioning, interpreting of the output, predicting the output, detailed confusion matrix, deploying the Hosmer-Lemeshow test for checking whether the observed event rates match the expected event rates.
Kolmogorov Smirnov ChartData analysis with R, understanding the WALD test, MC Fadden’s pseudo R-squared, the significance of the area under ROC Curve, Kolmogorov Smirnov Chart which is non-parametric test of one dimensional probability distribution.
Database connectivity with RConnecting to various databases from the R environment, deploying the ODBC tables for reading the data, visualization of the performance of the algorithm using Confusion Matrix.
Integrating R with HadoopCreating an integrated environment for deploying R on Hadoop platform, working with R Hadoop, RMR package and R Hadoop Integrated Programming Environment, R programming for MapReduce jobs and Hadoop execution.
R Case StudiesLogistic Regression Case Study
In this case study you will get a detailed understanding of the advertisement spends of a company that will help to drive more sales. You will deploy logistic regression to forecast the future trends, detect patterns, uncover insights and more all through the power of R programming. Due to this the future advertisement spends can be decided and optimized for higher revenues.
Multiple Regression Case Study
You will understand how to compare the miles per gallon (MPG) of a car based on the various parameters. You will deploy multiple regression and note down the MPG for car make, model, speed, load conditions, etc. It includes the model building, model diagnostic, checking the ROC curve, among other things.
Receiver Operating Characteristic (ROC) case study
You will work with various data sets in R, deploy data exploration methodologies, build scalable models, predict the outcome with highest precision, diagnose the model that you have created with various real world data, check the ROC curve and more.
SAS Course Content
Introduction to SASIntroduction to Base SAS, Installation of SAS tool, Getting started with SAS, various SAS Windows – Log, Explorer, Output, Search, Editor, etc. working with data sets, overview of SAS Functions, Library Types and programming files
SAS Enterprise GuideImport/Export Raw Data files, reading and sub setting the data set, various statements like WHERE, SET, Merge
Hands-on Exercise – Import Excel file in workspace, Read data, Export the workspace to save data
SAS Operators & FunctionsVarious SAS Operators – Arithmetic, Logical, Comparison, various SAS Functions – NUMERIC, CHARACTER, IS NULL, CONTAINS, LIKE, Input/Put, Date/Time, Conditional Statements (Do While, Do Until, If, Else)
Hands-on Exercise – Apply logical, arithmetic operators and SAS functions to perform operations
Compilation & ExecutionUnderstanding about Input Buffer, PDV (Backend), learning what is Missover
Using VariablesDefining and Using KEEP and DROP statements, apply these statements, Format and Labels in SAS.
Hands-on Exercise – Use KEEP and DROP statements
Creation and Compilation of SAS Data setsUnderstanding Delimiter, dataline rules, DLM, Delimiter DSD, raw data files and execution, list input for standard data.
Hands-on Exercise – Use delimiter rules on raw data files
SAS ProceduresThe various SAS standard Procedures built-in for popular programs – PROC SORT, PROC FREQ, PROC SUMMARY, PROC RANK, PROC EXPORT, PROC DATASET, PROC TRANSPOSE, , PROC CORR etc.
Hands-on Exercise – Use SORT, FREQ, SUMMARY, EXPORT and other procedures
Input statement and formatted inputReading standard and non-standard numeric inputs with Formatted inputs, Column Pointer Controls, Controlling while a record loads, Line pointer control / Absolute line pointer control, Single Trailing , Multiple IN and OUT statements, DATA LINES statement and rules, List Input Method, comparing Single Trailing and Double Trailing.
Hands-on Exercise – Read standard and non-standard numeric inputs with Formatted inputs, Control while a record loads, Control a Line pointer, Write Multiple IN and OUT statements
SAS FORMATSAS FORMAT statements – standard and user-written, associating a format with a variable, working with SAS FORMAT, deploying it on PROC Data sets, comparing ATTRIB and FORMAT statements.
Hands-on Exercise – Format a variable, deploy format rule on PROC DATA set, Use ATTRIB statement
SAS GraphsUnderstanding PROC GCHART, various Graphs, Bar Charts – Pie, Bar, 3D, plotting variables with PROC GPLOT.
Hands-on Exercise – Plot graphs using PROC GPLOT Display charts using PROC GCHART
Interactive Data ProcessingSAS advanced data discovery and visualization, point-and-click analytics capabilities, powerful reporting tools.
Data Transformation FunctionCharacter Functions, Numeric Functions, Converting Variable Type.
Hands-on Exercise – Use Functions in data transformation
Output Delivery System (ODS)Introduction to ODS, Data Optimization, How to generate files (rtf, pdf, html, doc) using SAS
Hands-on Exercise – Optimize data, generate rtf, pdf, html and doc files
SAS MACROSMacro Syntax, Macro Variables, Positional Parameters in a Macro, Macro Step
Hands-on Exercise – Write a macro, Use positional parameters
PROC SQLSQL Statements in SAS, SELECT, CASE, JOIN, UNION, Sorting Data
Hands-on Exercise – Create sql query to select and add a condition
Use a CASE in select queryAdvanced Base SASBase SAS web-based interface and ready-to-use programs, advanced data manipulation, storage and retrieval, descriptive statistics.
Hands-on Exercise – Use web UI to do statistical operations
Summarization ReportsReport Enhancement, Global Statements, User-defined Formats, PROC SORT, ODS Destinations, ODS Listing, PROC FREQ, PROC Means, PROC UNIVARIATE, PROC REPORT, PROC PRINT
Hands-on Exercise – Use PROC SORT to sort the results, List ODS, Find mean using PROC Means, print using PROC PRINT
Splunk Developer Topics
Splunk Development conceptsIntroduction to Splunk, Splunk developer roles and responsibilities
Basic SearchingWriting Splunk query for search, Autocomplete to build a search, time range, refine search, work with events, identify the contents of search, control a search jobHands-on Exercise – Write a basic search queryUsing Fields in SearchesUnderstand Fields, Use Fields in Search, Use Fields Sidebar, regex field extraction using Field Extractor (FX), delimiter field Extraction using FXHands-on Exercise – Use Fields in Search, Use Fields Sidebar, Use Field Extractor (FX), delimit field Extraction using FXSaving and Scheduling SearchesWriting Splunk query for search, sharing, saving, scheduling and exporting search resultsHands-on Exercise – Schedule a search, Save a search result, Share and export a search result
Creating AlertsCreation of alert, explaining alerts and viewing fired alertsHands-on Exercise – Create an alert, view fired alerts
Scheduled ReportsDescribe and Configure Scheduled ReportsTags and Event TypesIntroduction to Tags in Splunk, deploying Tags for Splunk search, understanding event types and utility, generating and implementing event types in SearchHands-on Exercise – Deploy tags for Splunk search, generate and implement event types in Search
Creating and Using MacrosDefine Macros, Arguments and Variables in a MacroHands-on Exercise – Define a Macro with arguments and use variables in itWorkflowGET, POST, and Search workflow actionsHands-on Exercise – Create GET, POST, and Search workflowSplunk Search CommandsSearch Command study, search practices in general, search pipeline, specify indexes in search, syntax highlighting, autocomplete, search commands like tables, fields, sort, multikv, rename, rex & erexHands-on Exercise – Create search pipeline, specify indexes in search, highlight syntax, use autocomplete feature, use search commands like tables, fields, sort, multikv, rename, rex & erexTransforming CommandsUsing Top, Rare, Stats CommandsHands-on Exercise – Use Top, Rare, Stats CommandsReporting CommandsUsing following commands and their functions: addcoltotals, addtotals,top, rare,statsHands-on Exercise – Create reports using following commands and their functions: addcoltotals, addtotals
Mapping and Single Value Commandsiplocation, geostats, geom, addtotals commandsHands-on Exercise – Track ip using iplocation, get geo data using geostatsSplunk Reports & visualizationsExplore the available visualizations, create charts and time charts, omit null values and format resultsHands-on Exercise – Create time charts, omit null values and format results
Analyzing, Calculating and Formatting ResultsCalculating and analyzing results, value conversion, roundoff and format values, using eval command, conditional statements, filtering calculated search resultsHands-on Exercise – Calculate and analyze results, perform coversion on a data value, roundoff a numbers, use eval command, write conditional statements,apply filters on calculated search results
Correlating EventsSearch with Transactions, Report on Transactions, Group events using fields and time, Transaction vs StatsHands-on Exercise – Generate Report on Transactions, Group events using fields and timeEnriching Data with LookupsLearn about data lookups, example, lookup table, defining and configuring automatic lookup, deploying lookup in reports and searchesHands-on Exercise – Define and configure automatic lookup, deploy lookup in reports and searches
Creating Reports and DashboardsCreating search charts, reports and dashboards, Editing reports and Dashboard, Adding reports to dashboardHands-on Exercise – Create search charts, reports and dashboards, Edit reports and Dashboard, Add reports to dashboardGetting started with ParsingWorking with raw data for data extraction, transformation, parsing and previewHands-on Exercise – Extract useful data from raw data, perform transformation, parse different values and preview
Using PivotDescribe Pivot, Relationship between data model and pivot, select a data model object, create a pivot report, instant pivot from a search, add a pivot report to dashboardHands-on Exercise – Select a data model object, create a pivot report, create instant pivot from a search, add a pivot report to dashboardCommon Information Model (CIM) Add-OnWhat is Splunk CIM, Using the CIM Add-On to normalize dataHands-on Exercise – Use the CIM Add-On to normalize dataSplunk Administration Course Content
Overview of SplunkIntroduction to the Splunk 3 tier architecture, understanding the Server settings, control, preferences and licensing, the most important components of Splunk tool, the hardware requirements, conditions for installation of Splunk.
Splunk InstallationUnderstanding how to install and configure Splunk, index creation, input configuration in standalone server, the search preferences, installing Splunk in the Linux environment.
Splunk Installation in LinuxInstalling Splunk in the Linux environment, the various prerequisites, configuration of Splunk in Linux.
Distributed Management ConsoleIntroduction to the Splunk Distributed Management Console, index clustering, forwarder management and distributed search in Splunk environment, providing the right authentication to users, access control.
Introduction to Splunk AppIntroducing the Splunk app, managing the Splunk app, the various add-ons in Splunk app, deleting and installing apps from SplunkBase, deploying the various app permissions, deploying the Splunk app, apps on forwarder.
Splunk indexes and usersUnderstanding the index time configuration file and search time configuration file.
Splunk configuration filesLearning about the index time and search time configuration files in Splunk, installing the forwarders, configuring the output and inputs.conf, managing the Universal Forwarders.
Splunk Deployment ManagementDeploying the Splunk tool, the Splunk deployment Server, setting up the Splunk deployment environment, deploying the clients grouping in Splunk.
Splunk IndexesUnderstanding the Splunk Indexes, the default Splunk Indexes, segregating the Splunk Indexes, learning about Splunk Buckets and Bucket Classification, estimating index storage, creating new index.
User roles and authenticationUnderstanding the concept of role inheritance, Splunk authentications, native authentications, LDAP authentications.
Splunk Administration EnvironmentSplunk installation, configuration, data inputs, app management, Splunk important concepts, parsing machine-generated data, search indexer and forwarder.
Basic Production EnvironmentIntroduction to Splunk Configuration Files, Universal Forwarder, Forwarder Management, data management, troubleshooting and monitoring.
Splunk Search EngineConverting machine-generated data into operational intelligence, setting up Dashboard, Reports and Charts, integrating Search Head Clustering & Indexer Clustering.
Various Splunk Input MethodsUnderstanding the input methods, deploying scripted, Windows, network and agentless input types, fine-tuning it all.
Splunk User & Index ManagementSplunk User authentication and Job Role assignment, learning to manage, monitor and optimize Splunk Indexes.
Machine Data ParsingUnderstanding parsing of machine-generated data, manipulation of raw data, previewing and parsing, data field extraction.
Search Scaling and MonitoringDistributed search concepts, improving search performance, large scale deployment and overcoming execution hurdles, working with Splunk Distributed Management Console for monitoring the entire operation.
Deep Learning Course Content
Introduction to Machine LearningThe domain of machine learning and its implications to the artificial intelligence sector, the advantages of machine learning over other conventional methodologies.
Deep Learning TechniquesIntroduction to Deep Learning within machine learning, how it differs from all others methods of machine learning, training the system with training data, supervised and unsupervised learning, classification and regression supervised learning, clustering and association unsupervised learning, the algorithms used in these types of learning.
TensorFlow for Training Deep Learning ModelIntroduction to TensorFlowopen source software library for designing, building and training Deep Learning models, Python Library behind TensorFlow, Tensor Processing Unit (TPU) programmable AI accelerator by Google.
Introduction to Neural NetworksMapping the human mind with Deep Neural Networks, the various building block of Artificial Neural Networks, the architecture of DNN, its building blocks, the concept of reinforcement learning in DNN, the various parameters, layers, activation functions and optimization algorithms in DNN.
Using GPUs to train Deep Learning networksIntroduction to GPUs and how they differ from CPUs, the importance of GPUs in training Deep Learning Networks, the forward pass and backward pass training technique, the GPU constituent with simpler core and concurrent hardware.
Python Course Content
Introduction to PythonWhat is Python Language and features, Why Python and why it is different from other languages, Installation of Python, Anaconda Python distribution for Windows, Mac, Linux. Run a sample python script, working with Pyhton IDE’s. Running basic python commands – Data types, Variables,Keywords,etcHands-on Exercise – Install Anaconda Python distribution for your OS (Windows/Linux/Mac)Basic constructs of Python languageIndentation(Tabs and Spaces) and Code Comments (Pound # character); Variables and Names; Built-in Data Types in Python – Numeric: int, float, complex – Containers: list, tuple, set, dict – Text Sequence: Str (String) – Others: Modules, Classes, Instances, Exceptions, Null Object, Ellipsis Object – Constants: False, True, None, NotImplemented, Ellipsis, __debug__; Basic Operators: Arithmetic, Comparison, Assignment, Logical, Bitwise, Membership, Indentity; Slicing and The Slice Operator [n:m]; Control and Loop Statements: if, for, while, range(), break, continue, else;Hands-on Exercise – Write your first Python program Write a Python Function (with and without parameters) Use Lambda expression Write a class, create a member function and a variable, Create an object Write a for loop to print all odd numbersWrting Object Oriented Program in Python and connecting with DatabaseClasses – classes and objects, access modifiers, instance and class members OOPS paradigm – Inheritance, Polymorphism and Encapsulation in Python. Functions: Parameters and Return Types; Lambda Expressions, Making connection with Database for pulling data.File Handling, Exception Handling in PythonOpen a File, Read from a File, Write into a File; Resetting the current position in a File; The Pickle (Serialize and Deserialize Python Objects); The Shelve (Overcome the limitation of Pickle); What is an Exception; Raising an Exception; Catching an Exception;Hands-on Exercise – Open a text file and read the contents, Write a new line in the opened file, Use pickle to serialize a python object, deserialize the object, Raise an exception and catch itMathematical Computing with Python (NumPy)Arrays and Matrices, ND-array object, Array indexing, Datatypes, Array math Broadcasting, Std Deviation, Conditional Prob, Covariance and Correlation.Hands-on Exercise – Import numpy module, Create an array using ND-array, Calculate std deviation on an array of numbers, Calculate correlation between two variablesScientific Computing with Python (SciPy)Builds on top of NumPy, SciPy and its characteristics, subpackages: cluster, fftpack, linalg, signal, integrate, optimize, stats; Bayes Theorem using SciPyHands-on Exercise – Import SciPy, Apply Bayes theorem using SciPy on the given datasetData Visualization (Matplotlib)Plotting Grapsh and Charts (Line, Pie, Bar, Scatter, Histogram, 3-D); Subplots; The Matplotlib APIHands-on Exercise – Plot Line, Pie, Scatter, Histogram and other charts using MatplotlibData Analysis and Machine Learning (Pandas) OR Data Manipulation with PythonDataframes, NumPy array to a dataframe; Import Data (csv, json, excel, sql database); Data operations: View, Select, Filter, Sort, Groupby, Cleaning, Join/Combine, Handling Missing Values; Introduction to Machine Learning(ML); Linear Regression; Time SeriesHands-on Exercise – Import Pandas, Use it to import data from a json file,,Select records by a group and apply filter on top of that, View the records, Perform Linear Regression analysis, Create a Time SeriesNatural Language Processing, Machine Learning (Scikit-Learn)Introduction to Natural Language Processing (NLP); NLP approach for Text Data; Environment Setup (Jupyter Notebook); Sentence Analysis; ML Algorithms in Scikit-Learn; What is Bag of Words Model; Feature Extraction from Text; Model Training; Search Grid; Multiple Parameters; Build a PipelineHands-on Exercise – Setup Jupyter Notebook environment, Load a dataset in Jupyter, Use algorithm in Scikit-Learn package to perform ML techniques, Train a model Create a search gridWeb Scraping for Data ScienceWhat is Web Scraping; Web Scraping Libraries (Beautifulsoup, Scrapy); Installation of Beautifulsoup; Install lxml Python Parser; Making a Soup Object using an input html; Navigating Py Objects in the Soup Tree; Searching the Tree; Output Print; Parsing Full or PartialHands-on Exercise – Install Beautifulsoup and lxml Python parser, Make a Soup object using an input html file, Navigate Py objects in the soup tree, Search tree, Print outputPython on HadoopUnderstanding Hadoop and its various components; Hadoop ecosystem and Hadoop common; HDFS and MapReduce Architecture; Python scripting for MapReduce Jobs on Hadoop frameworkHands-on Exercise – Write a basic MapReduce Job in Python and connect with Hadoop Framework to perform the taskWriting Spark code using PythonWhat is Spark,understanding RDDs, Spark Libs, writing Spark code using python,Spark Machine Libraries Mlib, Regression, Classification and Clustering using Spark MLlibHands-on Exercise – Implement sandbox, Run a python code in sandbox, Work with HDFS file system from sandboxTableau Course Content
Introduction to Data Visualization and Power of TableauWhat is data visualization, Comparision and benefits against reading raw numbers, Real usage examples from various business domains, Some quick powerful examples using Tableau without going into the technical details of TableauArchitecture of TableauInstallation of Tableau Desktop, Architecture of Tableau, Interface of Tableau (Layout, Toolbars, Data Pane, Analytics Pane etc), How to start with Tableau, Ways to share and exporting the work done in TableauHands-on Exercise – Play with the tableau desktop, interface to learn its user interface, Share an existing work, Export an existing workWorking with Metadata & Data BlendingConnection to Excels, PDFs and Cubes, Managing Metadata and Extracts, Data Preparation and dealing with NULL values, Data Joins (Inner, Left, Right, Outer) and Union, Cross Database joining, Data BlendingHands-on Exercise – Connect to an excel sheet and import data, Use metadata and extracts, Handle NULL values, Clean up the data before the actual use, Perform various join techniques, Perform data blending from more than one sourcesCreation of setsMarks, Highlighting, Sort and Group, Working with Sets (Creation of sets, Editing sets, IN/OUT, Sets in Hierarchies)Hands-on Exercise – Create and edit sets using Marks, Highlight desired items, Make groups, Applying sorting on result, Make hierachies in the created setWorking with FiltersFilters (Addition and Removal), Filtering continuous dates, dimensions, measures, Interactive FiltersHands-on Exercise – Add Filter on data set by date/dimensions/measures, Use interactive filter to views, Remove some filters to see the resultOrganizing Data and Visual AnalyticsFormatting Data (Labels, Annotations, Tooltips, Edit axes), Formatting Pane (Menu, Settings, Font, Alignment, Copy-Paste), Trend and Reference Lines, Forecasting, k-means Cluster Analysis in TableauHands-on Exercise – Apply labels, annotations, tooltips to graphs, Edit the attributes of axes, Set a reference line, Do k-means cluster analysis on a datasetWorking with MappingCoordinate points, Plotting Longitude and Latitude, Editing Unrecognized Locations, Custom Geocoding, Polygon Maps, WMS: Web Mapping Services, Background Image (Add Image, Plot Points on Image, Generate coordinates from Image)Hands-on Exercise – Plot latitude and longitude on geo map, Edit locations on the map, Create custom geocoding, Use images of a map and plot points on it, find coordinates in the image, Create a polygon map, Use WMS
This course is listed under Open Source , Development & Implementations , Industry Specific Applications , Data & Information Management , Networks & IT Infrastructure and Quality Assurance & Testing CommunityRelated Posts:Attended this course? Write a Review
Awards & Accolades for MyTechLogy Winner of
Winner of
REDHERRING
Top 100 Asia Finalist at SiTF Awards 2014 under the category Best Social & Community Product
Finalist at SiTF Awards 2014 under the category Best Social & Community Product Finalist at HR Vendor of the Year 2015 Awards under the category Best Learning Management System
Finalist at HR Vendor of the Year 2015 Awards under the category Best Talent Management Software
Finalist at HR Vendor of the Year 2015 Awards under the category Best Learning Management System
Finalist at HR Vendor of the Year 2015 Awards under the category Best Talent Management Software

