Death of Sample Survey in hands of Big Data
Published on 20 May 16
 Anindya Sankar
Anindya Sankar1
2
Rice Test
How one does usually comes to know that the rice they have put in the cooker is well cooked? Ask any one in the household and the answer is to take few grains of rice at random from cooker, see if they are cooked. If it’s so, then we can more or less safely assume that all the rice in the cooker is well cooked.
Now think of a scenario, where you are asked that to understand whether all the rice is cooked you must go ahead and test almost all the rice in the cooker, and you invest most of your time developing methodologies/technologies that will let you test all the rice grain in the cooker in the fastest possible way. But even after all the improvement one can do, will it really be more effective than checking few grains of rice and concluding whether all rice is cooked? May be it will be more effective but often one might find that it’s almost similar to the result obtained by testing few grains of rice.
Well the first idea I described is what is typically known as random sampling whereas second idea is what we really loosely call big data analytics these days anyways.
Now think of a scenario, where you are asked that to understand whether all the rice is cooked you must go ahead and test almost all the rice in the cooker, and you invest most of your time developing methodologies/technologies that will let you test all the rice grain in the cooker in the fastest possible way. But even after all the improvement one can do, will it really be more effective than checking few grains of rice and concluding whether all rice is cooked? May be it will be more effective but often one might find that it’s almost similar to the result obtained by testing few grains of rice.
Well the first idea I described is what is typically known as random sampling whereas second idea is what we really loosely call big data analytics these days anyways.
Sample Survey in Analytics
Traditional analytics deals with finding out causal relation among variables and statisticians were doing that since age immemorial when the corporate world used to take decisions by business sense and gut feelings. The computers were not as developed as it is now. Databases were still getting formulated and many people were still coding in C/C++ and some people even in FORTRAN. But still analysis was getting done, and more often than less was accurate enough due to the beautiful theories that was developed under the umbrella of sample survey.
Ask any statistician what sample survey is and they will tell you that it is a statistical procedure where you can understand characteristics of a large population by looking at the characteristics of a randomly chosen few. It does sound like how everyone usually checks whether rice in cooker is cooked or not, right?
In the initial age of analytics, what we call descriptive analytics, people use to prepare reports where they used to convert data into useful pieces of information for their customers. And no one use to take all data available in their systems to finish this work. Usually they used to use smaller amount of data, get the relevant information from it and send it across. And all businesses that consumed this data were able to make better decisions using the provided information. Even in today’s world for this purpose no one looks into entire data set. Even if you have petabytes of data stored somewhere, you still look at samples to get relevant information. Let me explain how the simplest sampling technique, a simple random sample with replacement(SRSWR) works and gives someone one critical information about their data, the mean.
Your data size is N, you decided to take a sample of size n such that none of the n. Choose random numbers from random number tables (computer can generate these nowadays) , and choose sample units that correspond to the number.
Then the sample mean
Ask any statistician what sample survey is and they will tell you that it is a statistical procedure where you can understand characteristics of a large population by looking at the characteristics of a randomly chosen few. It does sound like how everyone usually checks whether rice in cooker is cooked or not, right?
In the initial age of analytics, what we call descriptive analytics, people use to prepare reports where they used to convert data into useful pieces of information for their customers. And no one use to take all data available in their systems to finish this work. Usually they used to use smaller amount of data, get the relevant information from it and send it across. And all businesses that consumed this data were able to make better decisions using the provided information. Even in today’s world for this purpose no one looks into entire data set. Even if you have petabytes of data stored somewhere, you still look at samples to get relevant information. Let me explain how the simplest sampling technique, a simple random sample with replacement(SRSWR) works and gives someone one critical information about their data, the mean.
Your data size is N, you decided to take a sample of size n such that none of the n. Choose random numbers from random number tables (computer can generate these nowadays) , and choose sample units that correspond to the number.
Then the sample mean
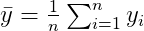
is often close enough to the actual population mean because of the following property.
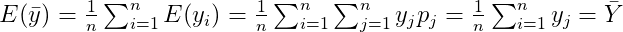
where p_j = 1/N is the probability of selecting jth unit in the sample under SRSWR. This property of the sample mean is called the property of unbiased estimation. And this does not hold true only for mean but for a host of measure including correlation and regression coefficients and hence also applicable to modern day analytics , more precisely in field of predictive and prescriptive analytics. And it was being used before the advent of big data, and is still used now, though no one talks about it any more
Death of sample survey – Big Data, Data Science & Machine Learning
In recent years we saw a huge boom in computing power and technology. And with it came big data. Everyone these days want to tag themselves as big data specialist without considering to find answer to the simplest two questions:-
There is no right answer to the question 1, and hence is debatable. But there is a definite answer to question 2.
If your business problem need a massive scaling up across regions, countries, etc. such that the analytics outcome is different for them following the same analytical methods then you do need it. If your business problem is to assist business with real time data processing of large volume of structured and unstructured data, you need big data analytics. But if your business problem can be solved by any of the statistical, sorry machine learning algorithms, and the objective is to build standalone models, you do not need big data.
I remember an incident in my early career, when SAS was still the champion analytics software, Logistic Regression can solve 90% of your analytics problem and Hadoop is still whispers in analytics companies, I was trying to solve a problem where I had millions of records of individuals and lots of data about them. My objective was to understand what characteristics of individuals trigger certain behavior. Manually getting the data into SAS was taking a long time, and worried I went to one of our analytics manager who was a statistician to the core. I asked him how I should deal with it. I was hopeful that he might suggest we try out the emerging field of Hadoop, etc. and then I will learn something new. He in return asked me whether I have forgotten statistics after joining the corporate. Reason being, I could have just taken a random sample of 30-40% of the data to get my answers and not worry about the rest of the data at all. And it worked beautifully. After the project for my own interest I did it again using the full data, and the result difference was negligible. The random sampling reduced the effort and time tremendously.
The reason I went into the above example in details because I see that people faces the same challenge today. They face such problem, without understanding they try to use big data technology and finally struggle to get good results out of it.
Another violent trend I see in the analytics domain is people dabbling into statistical/machine learning models without understanding the rationale behind it and hoping that the magic wand of machine learning will give good results if one keeps on feeding it with data. What they do not realize is the donkey you are beating may run a little faster than before but will never ever become a horse. If you have a bad model, you have a bad model. So it’s better to check why you have the bad model rather than re training the model with more data. Only if you see a legitimate improvement by incorporating more data to the training data, then you should think of adding more data.
The easy access to big data technology these days is what is really killing the subtle art of sample survey.
- How big is big data?
- Do I really need analytics on top of big data?
There is no right answer to the question 1, and hence is debatable. But there is a definite answer to question 2.
If your business problem need a massive scaling up across regions, countries, etc. such that the analytics outcome is different for them following the same analytical methods then you do need it. If your business problem is to assist business with real time data processing of large volume of structured and unstructured data, you need big data analytics. But if your business problem can be solved by any of the statistical, sorry machine learning algorithms, and the objective is to build standalone models, you do not need big data.
I remember an incident in my early career, when SAS was still the champion analytics software, Logistic Regression can solve 90% of your analytics problem and Hadoop is still whispers in analytics companies, I was trying to solve a problem where I had millions of records of individuals and lots of data about them. My objective was to understand what characteristics of individuals trigger certain behavior. Manually getting the data into SAS was taking a long time, and worried I went to one of our analytics manager who was a statistician to the core. I asked him how I should deal with it. I was hopeful that he might suggest we try out the emerging field of Hadoop, etc. and then I will learn something new. He in return asked me whether I have forgotten statistics after joining the corporate. Reason being, I could have just taken a random sample of 30-40% of the data to get my answers and not worry about the rest of the data at all. And it worked beautifully. After the project for my own interest I did it again using the full data, and the result difference was negligible. The random sampling reduced the effort and time tremendously.
The reason I went into the above example in details because I see that people faces the same challenge today. They face such problem, without understanding they try to use big data technology and finally struggle to get good results out of it.
Another violent trend I see in the analytics domain is people dabbling into statistical/machine learning models without understanding the rationale behind it and hoping that the magic wand of machine learning will give good results if one keeps on feeding it with data. What they do not realize is the donkey you are beating may run a little faster than before but will never ever become a horse. If you have a bad model, you have a bad model. So it’s better to check why you have the bad model rather than re training the model with more data. Only if you see a legitimate improvement by incorporating more data to the training data, then you should think of adding more data.
The easy access to big data technology these days is what is really killing the subtle art of sample survey.
Is sample survey dead then?
The answer is yes and no. It still exists but not all parts of it. Ask any data scientist about the steps needed to build a statistical model, they will always say that there is a step, where your divide your data into training, test and validation dataset usually in the ratio of 60%,20%,20%. And the way you get this splits is through random sampling. So it is still used but the name is almost dead in modern day data science. The nuance is people do not realize that if you have just 100 records then 60% or even 70% records are needed to build good models. But when you have 100,000 records , a model built with 60,000 records is not greatly better than a model built with 40,000 records and with proper sampling techniques there are possibilities to improve accuracy using lesser data size as well.
This blog is listed under
Development & Implementations
, Industry Specific Applications
and Data & Information Management
Community
Related Posts:
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!








Great post, Anindya! I totally agree with you when you say "If you have a bad model, you have a bad model". Could you please share your thoughts on the risk factors that might lead to producing a bad model?