How to Build a Natural Language Processing App
Published on 27 March 17
 Michelle
Michelle0
1
BY Sean wang
Natural language processing—a technology that allows software applications to process human language—has become fairly ubiquitous over the last few years.
Google search is increasingly capable of answering natural-sounding questions, Apple’s Siri is able to understand a wide variety of questions, and more and more companies are using (reasonably) intelligent chat and phone bots to communicate with customers. But how does this seemingly smart software really work?
In this article, you will learn about the technology that makes these applications tick, and you will learn how to develop natural language processing software of your own.
The article will walk you through the example process of building a news relevance analyzer. Imagine you have a stock portfolio, and you would like an app to automatically crawl through popular news websites and identify articles that are relevant to your portfolio. For example, if your stock portfolio includes companies like Microsoft,1
Getting Started with the Stanford NLP Library
Natural language processing apps, like any other machine learning apps, are built on a number of relatively small, simple, intuitive algorithms working in tandem. It often makes sense to use an external library where all of these algorithms are already implemented and integrated.
For our example, we will use the Stanford NLP library, a powerful Java-based natural-language processing library that comes with support for many languages.
One particular algorithm from this library that we are
The exact mechanics of the POS tagger algorithm is beyond the scope of this article, but you can learn more about it here.
To begin, we’ll create a new Java project (you can use your favorite IDE) and add the Stanford NLP library to the list of dependencies. If you are using Maven, simply add it to yourpom.xml file: 2
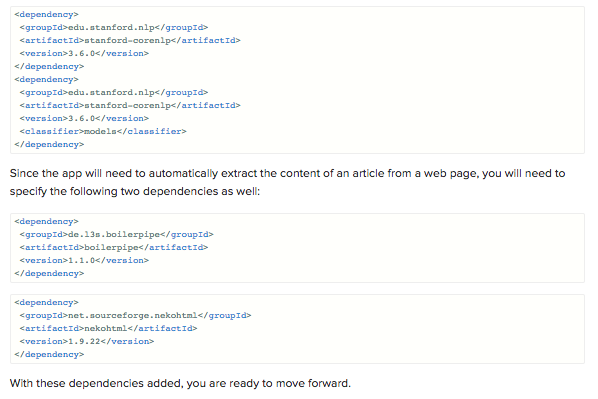
Scraping and Cleaning Articles
The first part of our analyzer will involve retrieving articles and
When retrieving articles from news sources, the pages are usually riddled with extraneous information (embedded videos, outbound links, videos, advertisements, etc.) that are irrelevant to the article itself. This is where Boilerpipe comes into play.
Boilerpipe is an extremely robust and efficient algorithm for removing clutter that identifies the main content of a news article by analyzing different content blocks using features like
extractFromURL, that will take a URL and use Boilerpipe to return the most relevant text as a string using ArticleExtractor for this task: 5

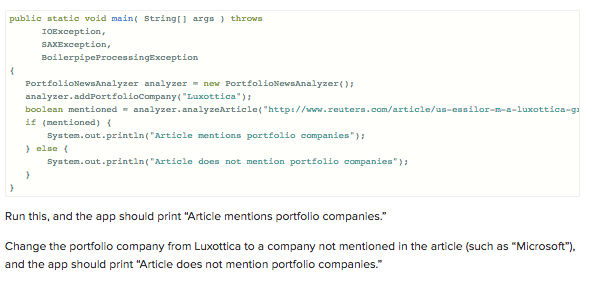
Now you can try it out with an example article regarding the mergers of optical giants Essilor and Luxottica, which you can find here. You can feed this URL to the function and see what comes out.
Add the following code to your main function: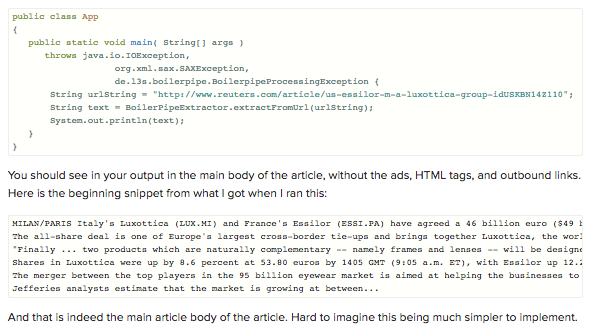
Tagging Parts of Speech
Now that you have successfully extracted the main article body, you can work on determining if the article mentions companies that are of interest to the user.
You may be tempted to simply do a string or regular expression search, but there are several disadvantages to this approach.
First of all, a string search may be prone to false positives. An article that mentions Microsoft Excel may be tagged as mentioning Microsoft, for instance.
Secondly, depending on the construction of the regular expression, a regular expression search can lead to false negatives. For example, an article that contains the phrase Luxottica’s quarterly earnings exceeded expectations may be missed by a regular expression search that searches for Luxottica surrounded by white spaces.
Finally, if you are interested in a large number of companies and are processing a large number of articles, searching through the entire body of the text for every company in the user’s portfolio may prove extremely time-consuming, yielding unacceptable performance.
Stanford’s CoreNLP library has many powerful features and provides a way to solve all three of these problems.
For our analyzer, we will use the Parts-of-Speech (POS) tagger. In particular, we can use the POS tagger to find all the proper nouns in the article and compare them to our portfolio of interesting stocks.
By incorporating NLP technology, we not only improve the accuracy of our tagger and minimize false positives and negatives mentioned above, but we also dramatically minimize the amount of text we need to compare to our portfolio of
By pre-processing our portfolio into a data structure that has low membership query cost, we can dramatically reduce the time needed to analyze an article.
Stanford CoreNLP provides a very convenient tagger called MaxentTagger that can provide POS Tagging in just a few lines of code.
Here is a simple implementation:1

Processing the Tagged Output into a Set
So far, we’ve built functions to download, clean, and tag a news article. But we still need to determine if the article mentions any of the companies of interest to the user.
To do this, we need to collect all the proper nouns and check if stocks from our portfolio are included in those proper nouns.
To find all the proper nouns, we will first want to split the tagged string output into tokens (using spaces as the delimiters), then split each of the tokens on the underscore (_) and check if the part of speech is a proper noun.
Once we have all the proper nouns, we will want to store them in a data structure that is better optimized for our purpose. For our example, we’ll use a HashSet. In exchange for disallowing duplicate entries and not keeping track of the order of the entries, HashSet allows very fast membership queries. Since we are only interested in querying for membership, the HashSet is perfect for our purposes.
PortfolioNewsAnalyzer class: 
Now the function should return a set with the individual proper nouns and the consecutive proper nouns (i.e., joined by spaces). If you print the
propNounSet, you should see something like the following: 2

Comparing the Portfolio against the PropNouns Set
We are almost done!
In the previous sections, we built a scraper that can download and extract the body of an article, a tagger that can parser the article body and identify proper nouns, and a processor that takes the tagged output and collects the proper nouns into a HashSet. Now all that’s left to do is to take the HashSet and compare it with the list of companies that we’re interested in.
PortfolioNewsAnalyzer class: 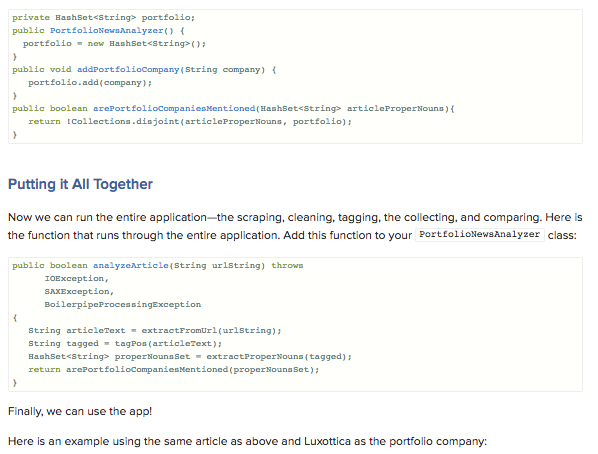
Building an NLP App Doesn't Need to be Hard
In this article, we stepped through the process of building an application that downloads an article from
I hope this article introduced you to useful concepts and techniques in natural language processing and that it inspired you to write natural language applications of your own.
[Note: You can find a copy of the code referenced in this article here.]
1

https://www.toptal.com/algorithms/how-to-build-a-natural-language-processing-app
From Siri to Cortana, software increasingly works with natural language. In this article, learn some techniquest to build a simple NLP app.
This blog is listed under
Development & Implementations
and Data & Information Management
Community
Related Posts:
Post a Comment
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!







