Basic Computation of esProc Table Sequence and Record Sequence
Published on 09 September 14
 Raqsoft
Raqsoft0
0
esProc table sequence is a structured two-dimensional table, boasting concepts like field, record, primary key and reference. These concepts originate from data table of relational database. A table sequence is also an explicit set of genericity and orderliness, which can make computation of structured data more flexibly. Record sequence is the reference of table sequence. They are closely related and their usages are almost the same. The article will explain their basic computation from aspects of accessing, maintenance, loop function, aggregate function and sets operations.
Accessing
1. Create objects
Description: Read two-dimensional structured data from a file, create table sequence objects and store them in cell A1. Create record sequence objects by referring to A1 and store them in B1.
Code:
A1=file("e:/sales.txt").import@t()
B1=A1.select(Amount>2000)
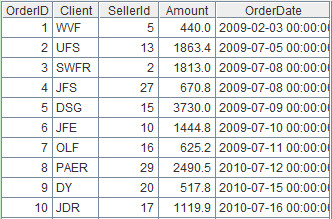
The first ten records in B1(record sequence):
Note: table sequence can be created according to a database or a file, or be created by inserting records within an empty object. A record sequence originates from a table sequence but it doesn’t store physical records. It only stores references of some records in the table sequence.
2. Access field values
Description: Get Client field of the fifth record in from A1 - the table sequence objects - and store it in cell A2. Get Client field of the first record from B1 - the record sequence objects - and store it in cell B2.
Code:
A2=A1(5).(Client) /computed result:DSG
B2=B1(1).(Client) /computed result:DSG
Note:
1. Since the first record in B1 correspond to the fifth record in A1, both of them have the same computed results.
2. Both table sequence and record sequence have completely same syntax for accessing field.
3. A field name can be replaced by the field’s sequence number and the result won’t change. For instance: A1(5).#2. Because this kind of replacement is employed universally in esProc, we won’t go into details about it.
4. Access column data
Description: Fetch column Client according to column name and store it in A3. Fetch column Client and column Amount according to column names and store them in A4. The record sequence and table sequence in this example have the same expression, and only the latter is selected for our illustration.
Code:
A3=A1.(Client)
A4=A1.new(Client,Amount)
Results are:
A3: 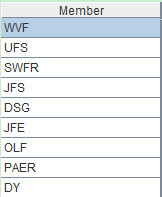
A4:
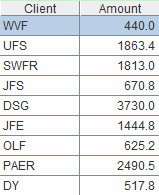
Note:
1. With the syntax “table sequence.(field name)†, only a column of data can be fetched, and the result is sequence without structured column name. With new function, however, a column or more columns of data can be fetched, and the result is table sequence with structured column name.
2. Whether the computing object is a table sequence or a sequence, new function will create a new table sequence, that is, the computed result of B1.new(Client,Amount) is also a table sequence.
4. Access row data
Description: Fetch the first two records according to row number. The record sequence and table sequence in this example have the same expression.
Code: =A1([1,2])

Maintenance
5. Add records
Description: Append a record r1 to table sequence A1, insert r2, of which only the OrderID field has value and the other fields are null, into the second row. Execute the same operation in record sequence B1.
Table sequence:
A6=A1.insert(0,152:OrderID,"CA":Client,5:SellerId,2961.40:Amount,"2010-12-5 0:00:00":OrderDate)
A7=A1.insert(2,153:OrderID)
Record sequence:
B6=create(OrderID,Client,SellerId,Amount,OrderDate) /empty table sequence B6
B7=B6.record([152,"CA",5,2961.40,"2010-12-5 00:00:00"]) /insert the first record r1 into B6
B8=B1.insert(0,B6(1)) /add r1 to B1
B9=B6.record([153,,,,]) /insert the second record r2 into B6
B10=B1.insert(2,B6(2)) /insert r2 into the second row of B1
Note:
1. The syntax of table sequence and record sequence has a lot of difference when new records are added to them. What is added to table sequence is physical records, and insert function can be directly used in table sequence A1. While for record sequence, only records’ references can be added to it, so the physical records must be there before making any references. In the example, the physical records are stored in B6(or A1 and B1).
2. After those computations are done, the records in B1 originate from two table sequences: A1 and B6.
3. If insert function’s first parameter is zero, add records at the end; if not, insert records into designated places. The rule applies in both table sequence and record sequence.
6. Delete records
Description: delete the record in the second row.
Table sequence:=A1.delete(2)
Record sequence:=B1.delete(2)
Note:What is deleted in table sequence is physical records; while those deleted in record sequence are references of records and the original table sequence won’t be affected with this operation.
7. Modify records
Description: Change the Amount field in the second record to 2000, and the OderDate field to 2009-07-01 00:00:00.
Table sequence:=A1(2).modify(2000:Amount,datetime("2009-07-01 00:00:00"):OrderDate)
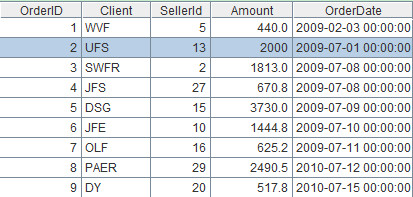
Record sequence:Record modification is forbidden in a sequence, it can only be executed in the original table sequence.
Note:In the example, modify function executes modification of a single record. But, it can do modification in batches in a table sequence.
8. Add fields
Description: Add two new fields - type and orderYear, in which type is null and orderYear is derived from the year in original OderDate field. The record sequence and table sequence in this example have the same expression.
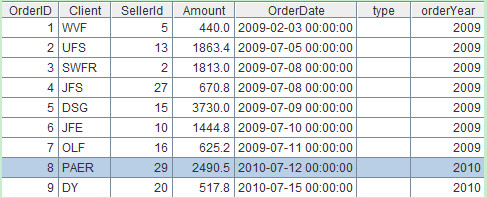
Note:Whether the computing object is a table sequence or a sequence, derive function will create a new table sequence.
Loop function
Loop function can compute each record of table sequence/record sequence, express complex loop statement with simple function. For instance, select is used to make query, sort to sequence, id to merge repeated records, pselect to fetch sequence number of eligible records and max if to read the maximum value from eligible records. Here the most basic ones - select function and sort function- will be illustrated.
9. Query
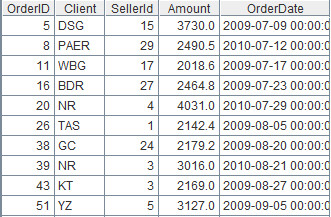
Description: Query out records whose Amount field is greater than or equal to 2000 and whose OrderDate is the year 2009. The record sequence and table sequence in this example have the same expression.
Table sequence:=A1.select(Amount>=2000 && year(OrderDate)==2009)
Results are: 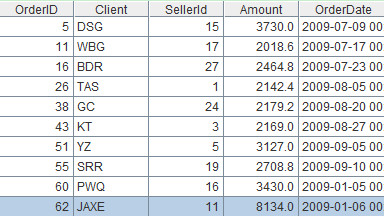
Note:Whether the computing object is table sequence or record sequence, the computed result of select function will always be a record sequence, that is, the references of records instead of physical records.
10. Sort
Description: Sort records in an ascending order according to SellerID fields. If the results of SellerID are the same, sort records in a descending order according to OrderDate fields. The record sequence and table sequence in this example have the same expression.
Code:=A1.sort(SellerId,OrderDate:-1)
Results are:
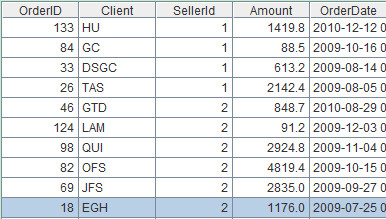
Note:Whether the computing object is table sequence or record sequence, the computed result of sort function will always be a record sequence. In fact, most of the functions for table sequence and record sequence can be employed universally unless the records are modified.
Aggregate function
11. Seek maximum value
Description:Seek the maximum value of Amount field. The record sequence and table sequence in this example have the same expression.
Code:A1.max(Amount)
Computed result:A2=29600.0
Note:Similar functions include min(minimum value), sum(summation), avg(average value), count(count), etc.
12. Sum by grouping
Description:Sum Amount in each group of data according to SellerID and the year, and count orders of each group. The record sequence and table sequence in this example have the same expression.
Code:A1.groups(SellerId,year(OrderDate);sum(Amount),count(~))

Note:
1. groups function will create a new table sequence.
2. “~†in expression count(~) represents the current group. count(~) can also be written as count(OrderID). Besides, we don’t designate field names of computed results in writing code, so default field names like year(OrderDate) will appear. A colon could be used in designated field names, such as =A1.groups(SellerId,year(OrderDate):OrderYear;sum(Amount),count(OrderID)) .
Operations between sets
Operations between sets include intersection â€^â€, union â€&â€, complement “\†and concatenate â€|â€, etc.
13. Intersection and union operations
Description:Store orders whose Amount is greater than and equal to 2000 in the year 2009 in A2, and store those whose SellerID is equal to 1 or 2 in A3. Now seek intersection and complement of A2 and A3, then store results respectively in A4 and A5.
Record sequence:
A2=A1.select(Amount>=2000 && year(OrderDate)==2009) /A2 is record sequence
A3=A1.select(SellerId==1 || SellerId==2) /A3 is record sequence
A4=A2^A3 /intersection, the result is record sequence
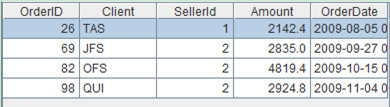
A5=A2\A3 /complement, remove members of A3 from A2

Table sequence:
A6=A2.new(OrderID,Client,SellerId,Amount,OrderDate)/table sequence created from A2
A7=A3.new(OrderID,Client,SellerId,Amount,OrderDate) /table sequence created from A3
A8=A6^A7 /Intersection, result is empty. A table sequence is a collection of physical members. Different table sequences always have different members, so the intersection operation of two table sequences is definitely empty. This has no practical significance in business.
A9=A6\A7 /Complement. Because members of two table sequences are always different, the computed result of complement is still A6.
Note:Only sets operations between record sequences originating from the same table sequence have practical significance in business. Usually, the intersection and complement operations between different table sequences or record sequences originating from different table sequences make no sense in business.
14. Union and concatenate operations
Description:Store orders of which SellerID equals 2 and 10 in A2, and store those of which SellerID equals 3 and 10 in A3. Now seek the union and concatenate of A2 and A3 and store results respectively in A4 and A5.
Record sequence:
A2=A1.select(SellerId==2 || SellerId==10)
A3=A1.select(SellerId==3 || SellerId==10)
A4=A2&A3 /Union. Members of A2 and A3 will combine in order and repeated records will be removed. 
A5=A2|A3 /concatenate. Members of A2 and A3 will combine in order and repeated records won’t be removed.
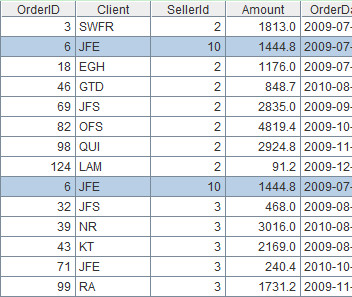
Table sequence:
A6=A2.new(OrderID,Client,SellerId,Amount,OrderDate) /table sequence created from A2
A7=A3.new(OrderID,Client,SellerId,Amount,OrderDate) /table sequence created from A2
A8=A6&A7 /Union. Members of two table sequences are completely different, so the union operation means a simple union-all of the two.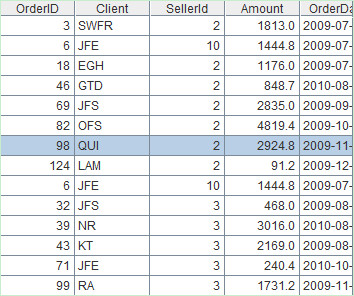
A9=A6|A7 /concatenate
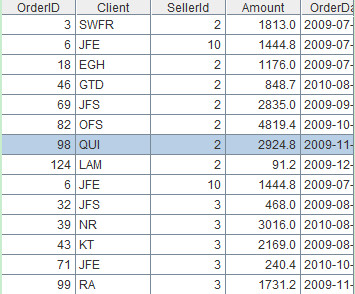
This blog is listed under
Data & Information Management
Community
Related Posts:
Post a Comment
You may also be interested in
Share your perspective

Share your achievement or new finding or bring a new tech idea to life. Your IT community is waiting!







