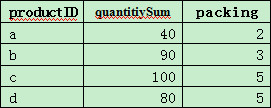
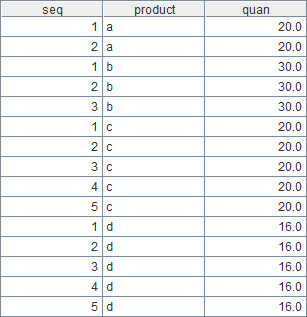
Please note the expression packing.new(…), which means creating a new table sequence according to the packing field of each record in A1. new function is used to create a new table sequence based on an existing sequence or table sequence, like ["a","b","c"].new() or [1,2,3…N].new(). The latter can be abbreviated to N.new(). If, for example, the value of packing field in the first record is 2, this expression will be parsed as [1,2].new(…). While creating a new table sequence using new function, we can use “~†to represent members of the original sequence. So ~:seq in the expression in A2 means using the original sequence as the first field of the new table sequence, with seq being the field name.
A2 represents the final result of this example.
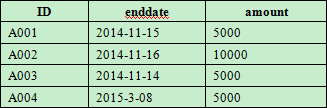
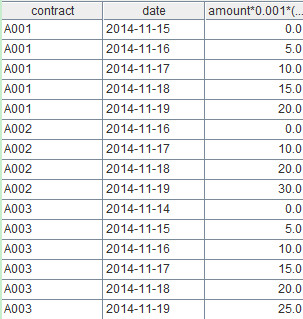
Now let’s look at another example that computes liquidated damages in a database. Here is a table - contract - that has multiple fields, three of which are ID (contract number), enddate (ending date) and amount (contract amount). Please compute how much liquidated damages should be paid each day for each breach of contract, on the assumption that the required liquidated damages per day is one thousandth of the contract amount.
Some of the data of contract are as follows:  Machine
Machine